KI-Sprachausgabe: Der umfassende Leitfaden zur Text-to-Speech-Technologie
KI-Sprachausgabe – Der umfassende Leitfaden zur Text-to-Speech-Technologie
Entdecken Sie die Technologie der KI-Sprachgenerierung, ihre Vorteile und bewährte Verfahren. Erfahren Sie, wie KI-Text-to-Speech-Systeme realistische Stimmen für Videos, Podcasts und andere Inhalte erzeugen.
KI-Sprachgenerierung
Wichtige Erkenntnis | Erläuterung |
|---|---|
Die Sprachqualität von KI im Jahr 2026 | Moderne Text-to-Speech-Technologie erzeugt eine fast menschenähnliche Sprachqualität mit natürlicher Intonation und emotionalem Ausdruck |
Sprachunterstützung | Führende Plattformen unterstützen über 100 Sprachen mit regionalen Akzenten und kulturellen Nuancen |
Funktionen zur Stimmklonung | Moderne Systeme können anhand kurzer Audioausschnitte bestimmte Stimmen nachahmen, um personalisierte Inhalte zu erstellen |
Echtzeitverarbeitung | Die heutige Technologie ermöglicht die sofortige Sprachausgabe für Live-Anwendungen und interaktive Inhalte |
Kommerzielle Anwendungen | Unternehmen nutzen KI-Stimmen für Marketingvideos, E-Learning, Barrierefreiheit und mehrsprachige Inhalte |
Kosteneffizienz | Die automatisierte Sprachsynthese senkt die Produktionskosten im Vergleich zu herkömmlichen Sprechern um 80 bis 90 % |
Inhaltsverzeichnis
Was ist KI-Sprachgenerierung?
So funktioniert die KI-Sprachgenerierung
Die wichtigsten Vorteile der KI-Sprachgenerierung
Häufige Herausforderungen und Fehler
Bewährte Verfahren für die KI-Sprachgenerierung im Jahr 2026
Quellen & Literaturhinweise
Häufig gestellte Fragen
Die KI-Sprachgenerierung revolutioniert die Art und Weise, wie Unternehmen Audioinhalte erstellen, und ermöglicht die sofortige Umwandlung von Text in natürlich klingende Sprache in mehreren Sprachen. Diese Technologie wandelt schriftliche Inhalte in lebensechte Sprachaufnahmen um, ohne dass menschliche Sprecher benötigt werden, und macht professionelle Audioproduktionen für Unternehmen jeder Größe zugänglich. Im Jahr 2026 hat diese innovative Text-zu-Sprache-Technologie ein beispielloses Maß an Realismus und Funktionalität erreicht. Die Auswirkungen dieser Technologie reichen weit über die einfache Umwandlung von Text in Sprache hinaus. Moderne KI-Sprachsysteme können spezifische Stimmmerkmale nachbilden, einen konsistenten emotionalen Ton beibehalten und sich sogar mit Videoinhalten synchronisieren, um nahtlose Multimedia-Erlebnisse zu ermöglichen. Für Unternehmen, die global expandieren, bietet die automatisierte Sprachsynthese die Möglichkeit, lokalisierte Inhalte schnell zu erstellen und gleichzeitig die Markenstimme in verschiedenen Märkten zu bewahren.

Was ist KI-Sprachgenerierung?
Die KI-Sprachgenerierung ist eine Technologie des maschinellen Lernens, die geschriebenen Text mithilfe künstlicher neuronaler Netze, die anhand umfangreicher Datensätze menschlicher Sprachmuster trainiert wurden, in gesprochene Sprache umwandelt. Dieser Prozess, auch als Text-to-Speech-Synthese (TTS) bekannt, erzeugt realistische Sprachausgabe, die menschliche Intonation, Rhythmus und Aussprache in verschiedenen Sprachen und mit unterschiedlichen Akzenten nachahmt.
Kerntechnologiekomponenten
Die Grundlage der Text-to-Speech-Technologie bilden mehrere miteinander verknüpfte Technologien, die zusammenwirken, um natürlich klingende Sprache zu erzeugen. Deep-Learning-Modelle analysieren sprachliche Muster, phonetische Strukturen und akustische Eigenschaften, um zu verstehen, wie Menschen auf natürliche Weise sprechen. Diese Systeme verarbeiten Text in mehreren Analyseebenen, von der einfachen Worterkennung bis hin zur komplexen Interpretation von Emotionen. Moderne KI-Sprachplattformen nutzen Transformer-Architekturen und generative gegnerische Netzwerke (GANs), um eine menschenähnliche Qualität zu erreichen. Laut einer Studie von ElevenLabs können führende Sprachgenerierungssysteme in kontrollierten Hörtests mittlerweile Sprache erzeugen, die von menschlichen Aufnahmen praktisch nicht zu unterscheiden ist [1]. Die Technologie hat sich von früheren Systemen mit roboterhaftem Klang zu ausgefeilten Plattformen entwickelt, die in der Lage sind, Emotionen auszudrücken und Persönlichkeitsmerkmale zu zeigen.
Entwicklung und aktuelle Funktionen
Der Weg von der einfachen computergestützten Sprachausgabe bis hin zur heutigen fortschrittlichen Sprachsynthese spiegelt jahrzehntelangen technologischen Fortschritt wider. Frühe Text-to-Speech-Systeme basierten auf der konkatenativen Synthese, bei der vorab aufgezeichnete Phoneme zu Wörtern zusammengefügt wurden. Dieser Ansatz führte zu einer abgehackten, unnatürlich klingenden Ausgabe, die sich eindeutig als maschinengeneriert zu erkennen gab. Aktuelle KI-Sprachsysteme nutzen neuronale Netze, die mit Millionen von Stunden menschlicher Sprachdaten trainiert wurden. Diese Modelle verstehen Kontext, Emotionen und subtile sprachliche Nuancen, die Sprache natürlich klingen lassen. Seit 2026 bieten Plattformen wie Speechify und LOVO Sprachbibliotheken mit Hunderten von unterschiedlichen Stimmen in über 60 Sprachen an [2]. Die Technologie unterstützt nun die Echtzeit-Generierung, das Klonen von Stimmen anhand minimaler Samples und die adaptive Tonanpassung für verschiedene Inhaltstypen.
Profi-Tipp: Testen Sie KI-Sprachplattformen bei der Bewertung mit Ihren eigenen Inhalten statt mit Demo-Skripten. Texte aus der Praxis enthalten oft Fachjargon, Eigennamen und komplexe Sätze, die Qualitätsunterschiede zwischen den Systemen deutlich machen.
So funktioniert die KI-Sprachgenerierung
Die automatische Sprachsynthese funktioniert über einen ausgeklügelten, mehrstufigen Prozess, der mithilfe fortschrittlicher Algorithmen des maschinellen Lernens und neuronaler Netzwerke Text in natürlich klingende Audioausgabe umwandelt.
Textverarbeitung und -analyse
Der Prozess der Sprachgenerierung beginnt mit einer umfassenden Textanalyse, bei der KI-Systeme den eingegebenen Inhalt zerlegen, um die sprachliche Struktur, den Kontext und die beabsichtigte Bedeutung zu erfassen. Algorithmen zur Verarbeitung natürlicher Sprache (NLP) identifizieren Satzgrenzen, Interpunktionsmerkmale und grammatikalische Beziehungen, die Sprachmuster beeinflussen. Das System analysiert jedes Wort hinsichtlich Ausspracheregeln, Betonungsmustern und phonetischer Darstellungen. Fortschrittliche Plattformen führen eine semantische Analyse durch, um den Kontext und emotionale Untertöne im Text zu erfassen. Diese Analyse hilft dabei, die angemessene Betonung, das Sprechtempo und die Intonationsmuster zu bestimmen. So löst beispielsweise ein Fragezeichen eine steigende Intonation aus, während Ausrufezeichen auf erhöhte Energie und Lautstärke hindeuten. Das System identifiziert zudem Eigennamen, Akronyme und Fachbegriffe, die eine spezielle Aussprache erfordern.
Verarbeitung mittels neuronaler Netze
Sobald die Textanalyse abgeschlossen ist, verarbeiten neuronale Netze die linguistischen Daten über mehrere Transformationsschichten hinweg, um eine Audioausgabe zu erzeugen. Die Kernverarbeitung umfasst mehrere spezialisierte Netzwerkkomponenten, die nacheinander ablaufen:
Encoder-Netzwerke wandeln Text-Token in dichte Vektordarstellungen um, die semantische und phonetische Informationen enthalten
Aufmerksamkeitsmechanismen erkennen Zusammenhänge zwischen Wörtern und Wortgruppen, die sich auf die Aussprache und Betonung auswirken
Dekodernetzwerke wandeln verarbeitete Vektoren in Mel-Spektrogramm-Darstellungen von Audiofrequenzen um
Vocoder-Netzwerke wandeln Spektrogramme in endgültige Audio-Wellenformen um, die für das menschliche Ohr hörbar sind
Moderne Systeme wie die von Typecast und Canva nutzen Transformer-Architekturen, die ganze Sätze gleichzeitig verarbeiten, anstatt Wort für Wort [3][4]. Diese parallele Verarbeitung ermöglicht ein besseres Kontextverständnis und einen natürlicheren Sprachfluss. Die neuronalen Netze wurden anhand vielfältiger Sprachdatensätze trainiert, die verschiedene Akzente, Sprechstile und emotionale Ausdrucksweisen widerspiegeln.
Profi-Tipp: Wählen Sie für mehrsprachige Inhalte Plattformen, die für jede Sprache eigene Modelle trainieren, anstatt auf universelle Modelle zurückzugreifen. Das sprachspezifische Training sorgt für eine genauere Aussprache und natürlich klingende Ergebnisse.
Der gesamte Prozess von der Texteingabe bis zur Audioausgabe dauert in der Regel nur wenige Sekunden, was Echtzeitanwendungen und interaktive Spracherlebnisse ermöglicht. Hochwertige Plattformen gewährleisten Konsistenz bei unterschiedlichen Textlängen und passen sich gleichzeitig an verschiedene Inhaltstypen und Sprechkontexte an.
Die wichtigsten Vorteile der KI-Sprachgenerierung
Die Text-to-Speech-Technologie bietet Unternehmen, die eine effiziente und skalierbare Produktion von Audioinhalten anstreben und dabei professionelle Qualität sowie globale Reichweite gewährleisten möchten, erhebliche Vorteile.
Kosteneffizienz und Skalierbarkeit
Bei der herkömmlichen Sprachproduktion müssen professionelle Sprecher engagiert, Studiozeiten gebucht und komplexe Aufnahmepläne koordiniert werden. Die automatisierte Sprachsynthese macht diese Gemeinkosten überflüssig und bietet gleichzeitig unbegrenzte Möglichkeiten zur Erstellung von Inhalten. Unternehmen können stundenlange Voiceover-Inhalte zum Preis einer einzigen professionellen Aufnahmesitzung produzieren. Die Vorteile der Skalierbarkeit werden besonders deutlich für Organisationen, die mehrsprachige Inhalte erstellen. Anstatt für jede Zielsprache Sprecher zu engagieren, können Unternehmen mit Plattformen wie LOVO oder FreeTTS [5][6] einheitliches Audiomaterial in über 100 Sprachen generieren. Dieser Ansatz verkürzt die Produktionszeiten von Wochen auf Stunden und gewährleistet gleichzeitig die Einhaltung der Qualitätsstandards in allen Sprachversionen. Kostenanalysen aus Branchenberichten zeigen, dass automatisierte Sprachsynthese die Kosten für die Audioproduktion im Vergleich zu herkömmlichen Methoden um 80–90 % senkt. Für E-Learning-Unternehmen, Marketingagenturen und Content-Ersteller ermöglicht diese Kostensenkung häufigere Inhaltsaktualisierungen und eine breitere Sprachabdeckung ohne Budgetbeschränkungen.
Geschwindigkeit und Beständigkeit
Die Text-to-Speech-Technologie liefert sofortige Ergebnisse und ermöglicht so eine schnelle Überarbeitung von Inhalten sowie die Erstellung von Audioinhalten in Echtzeit. Content-Ersteller können sofort Voiceovers generieren, verschiedene Sprachstile ausprobieren und sofortige Änderungen vornehmen, ohne dass Terminverzögerungen oder zusätzliche Kosten entstehen. Dieser Geschwindigkeitsvorteil erweist sich als entscheidend für zeitkritische Marketingkampagnen, aktuelle Nachrichten und dynamische Bildungsmaterialien. Ein weiterer wesentlicher Vorteil ist die Konsistenz, da KI-Stimmen bei unbegrenztem Inhaltsvolumen stets die gleiche Qualität, den gleichen Tonfall und die gleiche Aussprache beibehalten. Bei menschlichen Sprechern variieren die Leistungen aufgrund von Gesundheit, Stimmung und Umgebungsfaktoren naturgemäß von Aufnahmesitzung zu Aufnahmesitzung. KI-Systeme liefern hingegen vollkommen konsistente Ergebnisse und gewährleisten so die Einheitlichkeit der Markenstimme über alle Audioinhalte hinweg.
Herstellungsverfahren | Dauer | Stundenpreis | Flexibilität bei der Überarbeitung |
|---|---|---|---|
Professioneller Sprecher | 3–5 Tage | 500–2000 $ | Begrenzt/teuer |
KI-Sprachgenerierung | Protokoll | 10–50 $ | Unbegrenzt/Sofort |
Automatisierte Sprachausgabe (Basis) | Protokoll | 5–20 $ | Hoch/Sofort |
Wir bei Trame haben festgestellt, dass die automatisierte Sprachsynthese insbesondere bei Videolokalisierungsprojekten von Vorteil ist, bei denen die Lippensynchronisation über mehrere Sprachen hinweg eine präzise Steuerung der Audiolaufzeit erfordert. Herkömmliche Sprecher haben oft Schwierigkeiten, die genauen zeitlichen Vorgaben einzuhalten, während KI-Systeme perfekt getaktete Audiodaten erzeugen können, die mit den visuellen Inhalten übereinstimmen.
Barrierefreiheit und globale Reichweite
Die Text-to-Speech-Technologie verbessert die Barrierefreiheit von Inhalten für Menschen mit Sehbehinderungen, Leseschwierigkeiten oder Lernbehinderungen erheblich. Unternehmen können schriftliche Inhalte sofort in ein Audioformat umwandeln und so Informationen einem breiteren Publikum zugänglich machen, ohne dass zusätzliche Entwicklungszeit oder Ressourcen erforderlich sind. Dank der Mehrsprachigkeit dieser Technologie können Unternehmen globale Märkte effizient erschließen. Sie können lokalisierte Audioinhalte für ein internationales Publikum erstellen und dabei eine einheitliche Markenbotschaft gewährleisten. Optionen für regionale Akzente und kulturelle Anpassungen der Aussprache sorgen dafür, dass die Inhalte bei den lokalen Märkten authentisch ankommen.
Häufige Herausforderungen und Fehler
Trotz erheblicher technologischer Fortschritte birgt die automatisierte Sprachsynthese nach wie vor einige Herausforderungen und häufige Fehler bei der Implementierung, die Unternehmen kennen und angehen müssen, um eine erfolgreiche Einführung zu gewährleisten.
Fragen zu Qualität und Echtheit
Eine der größten Herausforderungen besteht darin, bei unterschiedlichen Inhaltstypen und Sprachen durchweg natürlich klingende Ergebnisse zu erzielen. Obwohl sich die Text-to-Speech-Technologie erheblich verbessert hat, weisen bestimmte Textmuster nach wie vor künstliche Merkmale auf. Fachjargon, Eigennamen und komplexe Satzstrukturen können zu unnatürlicher Aussprache oder einem holprigen Sprechtempo führen. Zu den häufigsten Qualitätsproblemen zählen:
Uneinheitliche Betonung wichtiger Wörter oder Ausdrücke innerhalb längerer Textabschnitte
Schwierigkeiten beim korrekten Umgang mit Abkürzungen, Akronymen und branchenspezifischer Terminologie
Unnatürliche Atemmuster oder Pausen, die nicht mit dem Sprachrhythmus eines Menschen übereinstimmen
Emotionale Diskrepanz, bei der die Stimme nicht die beabsichtigte Stimmung des Inhalts widerspiegelt
Fehler bei der Aussprache von Namen, Ortsnamen und kulturspezifischen Begriffen
Ein häufiger Fehler, den Unternehmen begehen, ist die Annahme, dass alle KI-Sprachplattformen die gleiche Qualität bieten. Zwischen den Anbietern bestehen erhebliche Unterschiede hinsichtlich Natürlichkeit, Sprachunterstützung und speziellen Funktionen. Tests mit echten Inhalten statt mit Demo-Skripten decken diese Qualitätsunterschiede auf, die sich auf die Benutzererfahrung auswirken.
Umsetzung und technische Herausforderungen
Die technische Umsetzung bringt oft unerwartete Komplikationen mit sich, die Projekte zur Sprachsynthese zum Scheitern bringen können. Herausforderungen bei der Integration treten auf, wenn APIs zur Sprachgenerierung mit bestehenden Content-Management-Systemen, Videobearbeitungs-Workflows oder E-Learning-Plattformen verbunden werden. Viele Unternehmen unterschätzen die technische Komplexität, die mit einer nahtlosen Integration verbunden ist. Verarbeitungsbeschränkungen stellen eine weitere erhebliche Herausforderung dar, insbesondere für Unternehmen mit hohem Content-Bedarf. Selbst fortschrittliche Plattformen wie QuillBot und NoteGPT weisen Nutzungsbeschränkungen und Verarbeitungsverzögerungen in Zeiten hoher Nachfrage auf [7][8]. Echtzeitanwendungen erfordern eine sorgfältige Architekturplanung, um Latenzzeiten zu bewältigen und eine konsistente Leistung zu gewährleisten. Zeichen- und Sprachbeschränkungen können die Flexibilität der Inhalte einschränken. Die meisten Plattformen legen Zeichenbeschränkungen pro Generierungsanfrage fest, was bei längeren Materialien eine Segmentierung der Inhalte erforderlich macht. Einige Systeme haben Schwierigkeiten mit mehrsprachigen Inhalten oder speziellen Formatierungsanforderungen, wie sie in technischen Dokumentationen oder Bildungsmaterialien häufig vorkommen.
Profi-Tipp: Testen Sie die automatische Sprachsynthese stets mit Ihren anspruchsvollsten Inhaltsszenarien – technischen Handbüchern, juristischen Dokumenten oder Texten mit vielen Abkürzungen. Diese Stresstests decken die Grenzen der Plattform auf, bevor sie vollständig eingeführt wird.
Ethische und rechtliche Überlegungen
Funktionen zum Klonen von Stimmen werfen wichtige ethische Fragen hinsichtlich der Einwilligung und des Missbrauchspotenzials auf. Die Technologie ermöglicht zwar legitime Anwendungen wie die Erhaltung von Stimmen für Patienten oder die Schaffung einheitlicher Markenstimmen, bietet aber auch Möglichkeiten für Täuschung und Betrug. Unternehmen müssen klare Richtlinien für die Nutzung von Stimmklonen festlegen und entsprechende Genehmigungen einholen. Urheberrechts- und Lizenzfragen erschweren die kommerzielle Nutzung von KI-Stimmen. Einige Plattformen schränken die kommerzielle Nutzung ein oder verlangen zusätzliche Lizenzen für geschäftliche Anwendungen. Das Verständnis dieser Einschränkungen beugt rechtlichen Komplikationen vor und gewährleistet die Einhaltung der Nutzungsbedingungen der Plattform. Bei der Nutzung cloudbasierter Sprachgenerierungsdienste ergeben sich Datenschutzbedenken. Hochgeladene Textinhalte können von Dienstanbietern gespeichert oder analysiert werden, wodurch sensible Geschäftsinformationen potenziell offengelegt werden. Unternehmen, die mit vertraulichen Inhalten umgehen, müssen Datenschutzrichtlinien prüfen und gegebenenfalls Lösungen vor Ort in Betracht ziehen.
Bewährte Verfahren für die KI-Sprachgenerierung im Jahr 2026
Die erfolgreiche Implementierung von Text-to-Speech-Technologie erfordert strategische Planung, eine sorgfältige Auswahl der Plattform und kontinuierliche Optimierung, um professionelle Ergebnisse zu erzielen, die den Geschäftszielen entsprechen.
Auswahl und Optimierung von Plattformen
Die Wahl der richtigen Sprachsynthese-Plattform hängt von den jeweiligen Anwendungsfällen, Qualitätsanforderungen und Integrationsbedürfnissen ab. Die führenden Plattformen im Jahr 2026 bieten für unterschiedliche Anwendungen jeweils spezifische Vorteile. ElevenLabs zeichnet sich durch Stimmklonen und emotionale Ausdruckskraft aus, während Speechify den Schwerpunkt auf Barrierefreiheit und Vorleseanwendungen legt [1][2]. Zu den wichtigsten Bewertungskriterien für die Plattformauswahl gehören:
Sprachqualität und Natürlichkeit in allen Ihren Zielsprachen
Zuverlässigkeit und Verarbeitungsgeschwindigkeit der API für Ihren Datenumsatz
Integrationsmöglichkeiten mit bestehenden Arbeitsabläufen und Systemen
Anpassung der Preisstruktur an die prognostizierten Nutzungsmuster
Verfügbare Sprachstile und Anpassungsoptionen
Nutzungsrechte für gewerbliche Zwecke und Lizenzbedingungen
Das Testen auf verschiedenen Plattformen mit realen Inhalten liefert den genauesten Qualitätsvergleich. Erstellen Sie Testskripte mit echten Geschäftsinhalten, einschließlich anspruchsvoller Elemente wie Fachbegriffe, Eigennamen und unterschiedlicher Satzstrukturen. Dieser Testansatz deckt praktische Unterschiede auf, die bei Demo-Inhalten möglicherweise nicht sichtbar werden.
Strategien zur Content-Optimierung
Die Optimierung von Inhalten für die automatisierte Sprachsynthese verbessert die Ausgabequalität und die Natürlichkeit erheblich. Gut strukturierte Texte liefern bessere Ergebnisse als Inhalte, die ausschließlich zum Lesen verfasst wurden. Berücksichtigen Sie bei der Erstellung von Inhalten die sprachliche Vortragsweise, einschließlich natürlicher Pausen, einer klaren Satzstruktur und angemessener emotionaler Hinweise. Zu den wirksamen Techniken zur Inhaltsoptimierung gehören:
Kürzere Sätze mit einer klaren Subjekt-Verb-Objekt-Struktur schreiben
einschließlich phonetischer Schreibweisen für ungewöhnliche Eigennamen oder Fachbegriffe
Hinzufügen von Interpunktionszeichen zur Steuerung des Tempos und zur Hervorhebung
Vermeidung übermäßiger Abkürzungen und Akronyme, die zu Verwirrung bei der Aussprache führen könnten
Inhalte mit natürlichen Sprachrhythmen und logischem Aufbau strukturieren
Bei Trame haben wir speziell für die mehrsprachige Sprachsynthese Inhaltsrichtlinien entwickelt, die eine einheitliche Qualität über alle Sprachen hinweg gewährleisten. Diese Richtlinien berücksichtigen kulturelle Präferenzen bei der Aussprache, die Auswahl regionaler Akzente sowie zeitliche Aspekte bei der Videosynchronisation.
Profi-Tipp: Erstellen Sie ein Aussprachewörterbuch für häufig verwendete Markennamen, Produktbegriffe und Fachjargon. Die meisten modernen Plattformen bieten die Möglichkeit, benutzerdefinierte Ausspracheregeln festzulegen, um die Einheitlichkeit aller Inhalte zu gewährleisten.
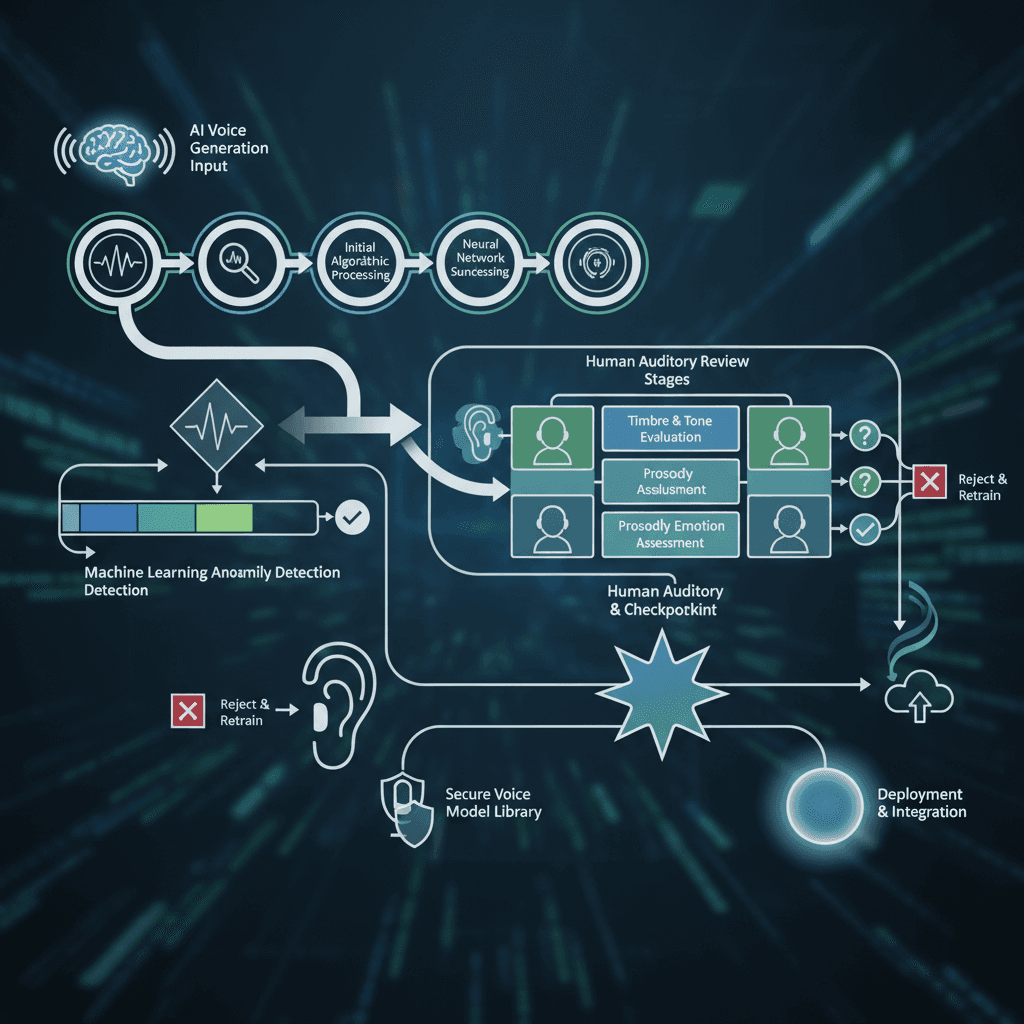
Qualitätssicherung und Workflow-Integration
Die Einrichtung robuster Qualitätssicherungsprozesse gewährleistet eine konsistente Sprachausgabe durch KI, die professionellen Standards entspricht. Entwickeln Sie Überprüfungsabläufe, die sowohl automatisierte Qualitätskontrollen als auch eine manuelle Validierung kritischer Inhalte umfassen. Automatisierte Tools können technische Probleme wie Audioartefakte oder Timing-Probleme erkennen, während menschliche Prüfer die Natürlichkeit und Angemessenheit bewerten. Effektive Qualitätssicherungs-Workflows umfassen mehrere Validierungsstufen. Eine erste automatisierte Überprüfung erfasst offensichtliche technische Probleme, gefolgt von einer inhaltlichen Überprüfung auf Richtigkeit und Angemessenheit des Tons. Die abschließende manuelle Validierung stellt sicher, dass die generierte Stimme den Markenstandards und den Erwartungen des Publikums entspricht. Die Integrationsplanung sollte sowohl technische als auch betriebliche Aspekte berücksichtigen. Die technische Integration umfasst API-Konnektivität, Dateiformatkompatibilität und Workflow-Automatisierung. Die betriebliche Integration umfasst Teamschulungen, Prozesse zur Freigabe von Inhalten und die Dokumentation von Qualitätsstandards.
Quellen & Literaturhinweise
ElevenLabs, „Kostenlose Plattform für KI-Stimmgeneratoren und Sprachassistenten“, 2026
Speechify, „Kostenloser KI-Stimmgenerator! KI-Sprecher, keine Anmeldung erforderlich“, 2026
Typecast, „KI-Stimmgenerator & Text-to-Speech | Voiceover-Tool“, 2026
LOVO, „Kostenloser KI-Stimmgenerator & Text-to-Speech“, 2026
FreeTTS, „Kostenlose Online-Text-to-Speech-Funktion – KI-Stimmgenerator“, 2026
QuillBot, „Kostenloser KI-Stimmgenerator | Erstellen Sie online realistische KI-Sprecher“, 2026
ResponsiveVoice, „ResponsiveVoice Text-to-Speech – ResponsiveVoice.JS KI-Text-to-Speech“, 2026
NiceVoice, „NiceVoice – Kostenloses Tool zum Klonen von Stimmen mittels KI“, 2026
Häufig gestellte Fragen
1. Wie realistisch klingt die KI-Stimmgenerierung im Jahr 2026?
Es ist unerlässlich, die Funktionsweise der KI-Sprachgenerierung zu verstehen. Moderne Text-to-Speech-Technologie liefert äußerst realistische Ergebnisse, die unter kontrollierten Bedingungen oft nicht von menschlicher Sprache zu unterscheiden sind. Führende Plattformen erzielen in professionellen Bewertungen Naturlichkeitswerte von über 95 %, wobei sich der emotionale Ausdruck und das Kontextverständnis kontinuierlich verbessern.
2. Kann die KI-Sprachgenerierung mehrere Sprachen präzise verarbeiten?
Ja, moderne Plattformen unterstützen über 100 Sprachen mit muttersprachlicher Aussprache und regionalen Akzenten. Die Qualität variiert je nach Sprache, wobei den wichtigsten Sprachen wie Englisch, Spanisch und Französisch die größte Entwicklungsaufmerksamkeit und die höchsten Genauigkeitsraten gewidmet werden.
3. Welche Kosten sind mit der KI-Sprachgenerierung verbunden?
Die Preise reichen von kostenlosen Tarifen mit eingeschränkter Nutzung bis hin zu Unternehmenspaketen, die monatlich zwischen 50 und 200 US-Dollar kosten. Die meisten Plattformen berechnen ihre Gebühren pro Zeichen oder Minute des generierten Audios, wobei für Nutzer mit hohem Datenvolumen Mengenrabatte angeboten werden. Für die kommerzielle Nutzung können zusätzliche Gebühren anfallen.
4. Ist das Klonen von Stimmen für geschäftliche Zwecke legal?
Das Klonen von Stimmen ist legal, wenn Sie die ausdrückliche Zustimmung des Stimminhabers haben oder wenn Sie Ihre eigene Stimme klonen. Bei geschäftlichen Anwendungen sind klare Einverständniserklärungen und angemessene Nutzungsrichtlinien erforderlich, um rechtliche Komplikationen und ethische Probleme zu vermeiden.
5. Wie schneidet die KI-Stimmengenerierung im Vergleich zu menschlichen Sprechern ab?
Die automatisierte Sprachsynthese bietet erhebliche Kosten- und Geschwindigkeitsvorteile und erreicht dabei bei den meisten Inhaltstypen eine nahezu menschengleiche Qualität. Menschliche Sprecher sind nach wie vor unübertroffen, wenn es um sehr emotionale Inhalte, kreative Interpretation und nuancierte Darbietungen geht, doch der Abstand wird immer geringer.
6. Können KI-Stimmen an spezifische Markenanforderungen angepasst werden?
Ja, viele Plattformen bieten Möglichkeiten zur Anpassung der Sprachausgabe, darunter Tonfall, Sprechtempo, Betonungsmuster und emotionale Merkmale. Mit fortschrittlichen Systemen lassen sich individuelle Stimmen trainieren, die auf bestimmte Markenpersönlichkeiten und Kommunikationsstile zugeschnitten sind.
7. Welche technischen Voraussetzungen sind für die Integration von KI-Sprachfunktionen erforderlich?
Die meisten Plattformen bieten REST-APIs an, deren Integration grundlegende Programmierkenntnisse erfordert. Cloud-basierte Lösungen benötigen eine zuverlässige Internetverbindung, während lokale Lösungen für die Echtzeitverarbeitung erhebliche Rechenressourcen erfordern.
8. Wie geht die KI-Stimmgenerierung mit der Aussprache von Fachbegriffen um?
Fortgeschrittene Plattformen verfügen über Aussprachewörterbücher und ermöglichen benutzerdefinierte phonetische Schreibweisen für Fachbegriffe. Bei Fachjargon und Eigennamen kann jedoch eine manuelle Aussprachehilfe erforderlich sein, um Genauigkeit und Konsistenz zu gewährleisten.
Die Text-to-Speech-Technologie stellt eine bahnbrechende Innovation dar, die die Art und Weise, wie Unternehmen Audioinhalte erstellen und verbreiten, grundlegend verändert. Im Jahr 2026 ist die Technologie so ausgereift, dass sie Ergebnisse in professioneller Qualität liefert und gleichzeitig eine beispiellose Skalierbarkeit und Kosteneffizienz bietet. Unternehmen, die automatisierte Sprachsynthese einsetzen, können durch schnellere Inhaltsproduktion, eine breitere Sprachabdeckung und verbesserte Barrierefreiheitsfunktionen erhebliche Wettbewerbsvorteile erzielen. Der Schlüssel zu einer erfolgreichen Implementierung liegt im Verständnis sowohl der Möglichkeiten als auch der Grenzen der aktuellen Technologie. Während sich die Sprachsynthese in vielen Anwendungsbereichen bewährt, erfordert sie eine sorgfältige Integrationsplanung, Inhaltsoptimierung und Qualitätssicherungsprozesse, um optimale Ergebnisse zu erzielen. Unternehmen, die in eine angemessene Bewertung, Tests und die Entwicklung von Arbeitsabläufen investieren, werden das volle Potenzial dieser leistungsstarken Technologie ausschöpfen können.

Für Unternehmen, die global expandieren oder die Barrierefreiheit ihrer Inhalte verbessern möchten, bieten Text-to-Speech-Lösungen einen effizienten Weg in die Zukunft. Die kontinuierliche Weiterentwicklung dieser Technologie verspricht noch leistungsfähigere Funktionen und macht sie zu einem unverzichtbaren Werkzeug für eine moderne Content-Strategie. Der Erfolg hängt davon ab, die richtige Plattform auszuwählen, die Inhalte entsprechend zu optimieren und Qualitätsstandards einzuhalten, die den Erwartungen der Zielgruppe entsprechen.
Über den Autor
Verfasst von den Experten für SaaS-basierte, KI-gestützte Lokalisierung und Übersetzung bei Trame. Unser Team verfügt über langjährige praktische Erfahrung in der Unterstützung von Unternehmen bei der SaaS-basierten, KI-gestützten Lokalisierung und Übersetzung und bietet praktische Anleitungen, die auf realen Ergebnissen basieren.
