AI Voice Generation: Complete Guide to Text-to-Speech Tech
ai-voice-generation-complete-guide-to-text-to-speech-tech
Discover AI voice generation technology, benefits, and best practices. Learn how text-to-speech AI creates realistic voices for videos, podcasts, and content.
AI voice generation
Key Insight | Explanation |
|---|---|
AI Voice Quality in 2026 | Modern text-to-speech technology produces near-human quality speech with natural intonation and emotional expression |
Language Support | Leading platforms support 100+ languages with regional accents and cultural nuances |
Voice Cloning Capabilities | Advanced systems can replicate specific voices from short audio samples for personalized content |
Real-Time Processing | Current technology enables instant voice generation for live applications and interactive content |
Commercial Applications | Businesses use AI voices for marketing videos, e-learning, accessibility, and multilingual content |
Cost Efficiency | Automated voice synthesis reduces production costs by 80-90% compared to traditional voice talent |
Table of Contents
What Is AI Voice Generation?
How AI Voice Generation Works
Key Benefits of AI Voice Generation
Common Challenges and Mistakes
Best Practices for AI Voice Generation in 2026
Sources & References
Frequently Asked Questions
AI voice generation is revolutionizing how businesses create audio content, enabling instant conversion of text into natural-sounding speech across multiple languages. This technology transforms written content into lifelike voiceovers without requiring human voice talent, making professional audio production accessible to organizations of all sizes. As of 2026, this innovative text-to-speech technology has reached unprecedented levels of realism and functionality. The technology's impact extends far beyond simple text-to-speech conversion. Modern AI voice systems can replicate specific vocal characteristics, maintain consistent emotional tone, and even synchronize with video content for seamless multimedia experiences. For businesses expanding globally, automated voice synthesis offers the ability to create localized content quickly while preserving brand voice across different markets.

What Is AI Voice Generation?
AI voice generation is a machine learning technology that converts written text into spoken audio using artificial neural networks trained on vast datasets of human speech patterns. This process, also known as text-to-speech (TTS) synthesis, creates realistic vocal output that mimics human intonation, rhythm, and pronunciation across multiple languages and accents.
Core Technology Components
The foundation of text-to-speech technology rests on several interconnected technologies working together to produce natural-sounding speech. Deep learning models analyze linguistic patterns, phonetic structures, and acoustic properties to understand how humans naturally speak. These systems process text through multiple layers of analysis, from basic word recognition to complex emotional interpretation. Modern AI voice platforms utilize transformer architectures and generative adversarial networks (GANs) to achieve human-like quality. According to research from ElevenLabs, leading voice generation systems can now produce speech that's virtually indistinguishable from human recordings in controlled listening tests [1]. The technology has evolved from robotic-sounding early systems to sophisticated platforms capable of emotional expression and personality traits.
Evolution and Current Capabilities
The journey from basic computerized speech to today's advanced voice synthesis represents decades of technological advancement. Early text-to-speech systems relied on concatenative synthesis, piecing together pre-recorded phonemes to form words. This approach produced choppy, unnatural-sounding output that clearly identified itself as machine-generated. Current AI voice systems leverage neural networks trained on millions of hours of human speech data. These models understand context, emotion, and subtle linguistic nuances that make speech sound natural. As of 2026, platforms like Speechify and LOVO offer voice libraries containing hundreds of distinct voices across 60+ languages [2]. The technology now supports real-time generation, voice cloning from minimal samples, and adaptive tone matching for different content types.
Pro Tip: When evaluating AI voice platforms, test them with your actual content rather than demo scripts. Real-world text often contains industry jargon, proper nouns, and complex sentences that reveal quality differences between systems.
How AI Voice Generation Works
Automated voice synthesis operates through a sophisticated multi-stage process that transforms text input into natural-sounding audio output using advanced machine learning algorithms and neural network architectures.
Text Processing and Analysis
The voice generation process begins with comprehensive text analysis where AI systems parse input content to understand linguistic structure, context, and intended meaning. Natural language processing (NLP) algorithms identify sentence boundaries, punctuation cues, and grammatical relationships that influence speech patterns. The system analyzes each word for pronunciation rules, stress patterns, and phonetic representations. Advanced platforms perform semantic analysis to understand context and emotional undertones within the text. This analysis helps determine appropriate vocal emphasis, pacing, and intonation patterns. For example, a question mark triggers rising intonation, while exclamation points indicate increased energy and volume. The system also identifies proper nouns, acronyms, and specialized terminology that require specific pronunciation handling.
Neural Network Processing
Once text analysis completes, neural networks process the linguistic data through multiple transformation layers to generate audio output. The core processing involves several specialized network components working in sequence:
Encoder networks convert text tokens into dense vector representations containing semantic and phonetic information
Attention mechanisms identify relationships between words and phrases that affect pronunciation and emphasis
Decoder networks transform processed vectors into mel-spectrogram representations of audio frequencies
Vocoder networks convert spectrograms into final audio waveforms that humans can hear
Modern systems like those used by Typecast and Canva employ transformer architectures that process entire sentences simultaneously rather than word-by-word [3][4]. This parallel processing enables better context understanding and more natural speech flow. The neural networks have been trained on diverse speech datasets representing different accents, speaking styles, and emotional expressions.
Pro Tip: For multilingual content, choose platforms that train separate models for each language rather than using universal models. Language-specific training produces more accurate pronunciation and natural-sounding results.
The entire process from text input to audio output typically completes in seconds, enabling real-time applications and interactive voice experiences. Quality platforms maintain consistency across different text lengths while adapting to various content types and speaking contexts.
Key Benefits of AI Voice Generation
Text-to-speech technology delivers substantial advantages for businesses seeking efficient, scalable audio content production while maintaining professional quality and global reach capabilities.
Cost Efficiency and Scalability
Traditional voice production requires hiring professional voice talent, booking studio time, and managing complex recording schedules. Automated voice synthesis eliminates these overhead costs while providing unlimited content creation capacity. Businesses can produce hours of voiceover content for the cost of a single professional recording session. The scalability benefits become particularly evident for organizations creating multilingual content. Instead of hiring voice talent for each target language, companies can generate consistent audio across 100+ languages using platforms like LOVO or FreeTTS [5][6]. This approach reduces production timelines from weeks to hours while maintaining quality standards across all language versions. Cost analysis from industry reports shows that automated voice synthesis reduces audio production expenses by 80-90% compared to traditional methods. For e-learning companies, marketing agencies, and content creators, this cost reduction enables more frequent content updates and broader language coverage without budget constraints.
Speed and Consistency
Text-to-speech technology produces immediate results, enabling rapid content iteration and real-time audio creation. Content creators can generate voiceovers instantly, test different vocal styles, and make immediate revisions without scheduling delays or additional costs. This speed advantage proves crucial for time-sensitive marketing campaigns, breaking news content, and dynamic educational materials. Consistency represents another significant benefit, as AI voices maintain identical quality, tone, and pronunciation across unlimited content volumes. Human voice talent naturally varies between recording sessions due to health, mood, and environmental factors. AI systems deliver perfectly consistent output, ensuring brand voice uniformity across all audio content.
Production Method | Time to Complete | Cost per Hour | Revision Flexibility |
|---|---|---|---|
Professional Voice Talent | 3-5 days | $500-2000 | Limited/Expensive |
AI Voice Generation | Minutes | $10-50 | Unlimited/Instant |
Automated TTS (Basic) | Minutes | $5-20 | High/Instant |
At Trame, we've found that automated voice synthesis particularly benefits video localization projects where maintaining lip-sync timing across multiple languages requires precise audio duration control. Traditional voice talent often struggles to match exact timing requirements, while AI systems can generate perfectly timed audio that aligns with visual content.
Accessibility and Global Reach
Text-to-speech technology significantly improves content accessibility for individuals with visual impairments, reading difficulties, or learning disabilities. Organizations can instantly convert written content into audio format, making information accessible to broader audiences without additional development time or resources. The technology's multilingual capabilities enable businesses to reach global markets efficiently. Companies can create localized audio content for international audiences while maintaining consistent brand messaging. Regional accent options and cultural pronunciation adaptations ensure content resonates authentically with local markets.
Common Challenges and Mistakes
Despite significant technological advances, automated voice synthesis still presents several challenges and common implementation mistakes that organizations must understand and address for successful deployment.
Quality and Authenticity Issues
One of the most persistent challenges involves achieving consistently natural-sounding output across different content types and languages. While text-to-speech technology has improved dramatically, certain text patterns still expose artificial characteristics. Technical jargon, proper nouns, and complex sentence structures can produce unnatural pronunciation or awkward pacing. Common quality issues include:
Inconsistent emphasis on important words or phrases within longer passages
Difficulty handling abbreviations, acronyms, and industry-specific terminology correctly
Unnatural breathing patterns or pauses that don't align with human speech rhythms
Emotional tone mismatches where the voice doesn't reflect the content's intended mood
Pronunciation errors for names, places, and culturally specific terms
A common mistake organizations make is assuming all AI voice platforms deliver identical quality. Significant differences exist between providers in terms of naturalness, language support, and specialized features. Testing with actual content rather than demo scripts reveals these quality variations that impact user experience.
Implementation and Technical Challenges
Technical implementation often presents unexpected complications that can derail voice synthesis projects. Integration challenges arise when connecting voice generation APIs with existing content management systems, video editing workflows, or e-learning platforms. Many organizations underestimate the technical complexity involved in seamless integration. Processing limitations represent another significant challenge, particularly for organizations with high-volume content needs. Even advanced platforms like QuillBot and NoteGPT have usage limits and processing delays during peak demand periods [7][8]. Real-time applications require careful architecture planning to handle latency and ensure consistent performance. Character and language limitations can restrict content flexibility. Most platforms impose character limits per generation request, requiring content segmentation for longer materials. Some systems struggle with mixed-language content or specialized formatting requirements common in technical documentation or educational materials.
Pro Tip: Always test automated voice synthesis with your worst-case content scenarios – technical manuals, legal documents, or content with heavy acronym usage. These stress tests reveal platform limitations before full deployment.
Ethical and Legal Considerations
Voice cloning capabilities raise important ethical questions about consent and misuse potential. While the technology enables legitimate applications like preserving voices for medical patients or creating consistent brand voices, it also creates opportunities for deception and fraud. Organizations must establish clear policies governing voice cloning usage and obtain appropriate permissions. Copyright and licensing issues complicate commercial AI voice usage. Some platforms restrict commercial usage or require additional licensing for business applications. Understanding these limitations prevents legal complications and ensures compliance with platform terms of service. Data privacy concerns arise when using cloud-based voice generation services. Uploaded text content may be stored or analyzed by service providers, potentially exposing sensitive business information. Organizations handling confidential content must evaluate privacy policies and consider on-premises solutions where necessary.
Best Practices for AI Voice Generation in 2026
Implementing text-to-speech technology successfully requires strategic planning, careful platform selection, and ongoing optimization to achieve professional results that meet business objectives.
Platform Selection and Optimization
Choosing the right voice synthesis platform depends on specific use cases, quality requirements, and integration needs. Leading platforms in 2026 offer distinct advantages for different applications. ElevenLabs excels in voice cloning and emotional expression, while Speechify focuses on accessibility and reading applications [1][2]. Key evaluation criteria for platform selection include:
Voice quality and naturalness across your target languages
API reliability and processing speed for your volume requirements
Integration capabilities with existing workflows and systems
Pricing structure alignment with projected usage patterns
Available voice styles and customization options
Commercial usage rights and licensing terms
Testing multiple platforms with actual content provides the most accurate quality comparison. Create evaluation scripts using real business content, including challenging elements like technical terms, proper nouns, and varied sentence structures. This testing approach reveals practical differences that demo content might not expose.
Content Optimization Strategies
Optimizing content for automated voice synthesis significantly improves output quality and naturalness. Well-structured text produces better results than content written solely for reading. Consider vocal delivery when crafting content, including natural pause points, clear sentence structure, and appropriate emotional cues. Effective content optimization techniques include:
Writing shorter sentences with clear subject-verb-object structure
Including phonetic spellings for unusual proper nouns or technical terms
Adding punctuation cues for desired pacing and emphasis
Avoiding excessive abbreviations and acronyms that may confuse pronunciation
Structuring content with natural speaking rhythms and logical flow
At Trame, we've developed content guidelines specifically for multilingual voice synthesis that ensure consistent quality across languages. These guidelines address cultural pronunciation preferences, regional accent selection, and timing considerations for video synchronization.
Pro Tip: Create a pronunciation dictionary for frequently used brand names, product terms, and industry jargon. Most advanced platforms allow custom pronunciation rules that improve consistency across all content.
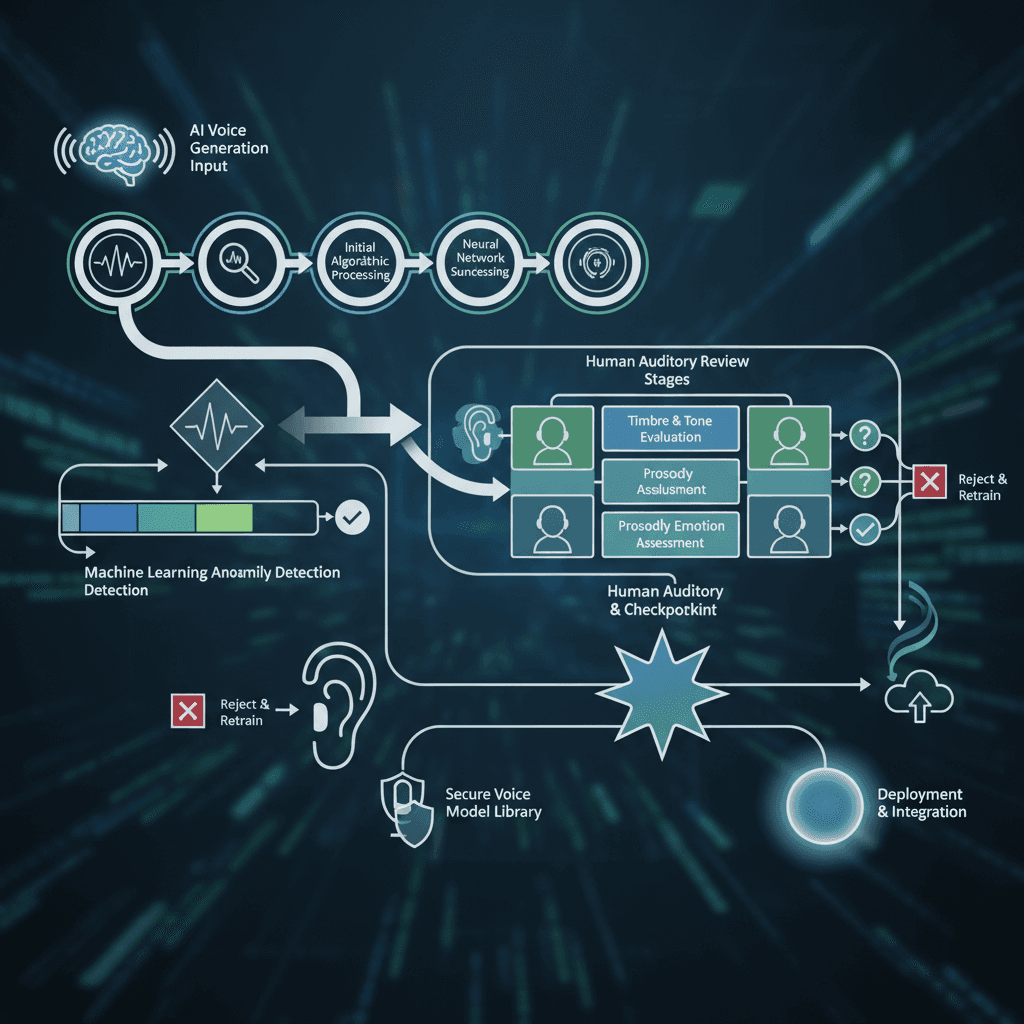
Quality Assurance and Workflow Integration
Establishing robust quality assurance processes ensures consistent AI voice output that meets professional standards. Develop review workflows that include both automated quality checks and human validation for critical content. Automated tools can identify technical issues like audio artifacts or timing problems, while human reviewers assess naturalness and appropriateness. Effective quality assurance workflows incorporate multiple validation stages. Initial automated screening catches obvious technical problems, followed by content review for accuracy and tone appropriateness. Final human validation ensures the generated voice aligns with brand standards and audience expectations. Integration planning should address both technical and operational considerations. Technical integration involves API connectivity, file format compatibility, and workflow automation. Operational integration covers team training, content approval processes, and quality standards documentation.
Sources & References
ElevenLabs, "Free AI Voice Generator & Voice Agents Platform", 2026
Speechify, "Free AI Voice Generator! AI voiceovers, no sign-up required", 2026
Typecast, "AI Voice Generator & Text-to-Speech | Voiceover Tool", 2026
FreeTTS, "Free Text to Speech Online - AI Voice Generator", 2026
QuillBot, "Free AI Voice Generator | Create Realistic AI Voiceover Online", 2026
NoteGPT, "Free AI Voice Generator - Create Voices Online, No Sign-up", 2026
ResponsiveVoice, "ResponsiveVoice Text To Speech - ResponsiveVoice.JS AI Text to Speech", 2026
Frequently Asked Questions
1. How realistic does AI voice generation sound in 2026?
Understanding AI voice generation is essential. Modern text-to-speech technology produces extremely realistic results that are often indistinguishable from human speech in controlled conditions. Leading platforms achieve 95%+ naturalness ratings in professional evaluations, with continued improvements in emotional expression and contextual understanding.
2. Can AI voice generation handle multiple languages accurately?
Yes, advanced platforms support 100+ languages with native pronunciation and regional accents. Quality varies by language, with major languages like English, Spanish, and French receiving the most development attention and highest accuracy rates.
3. What are the costs associated with AI voice generation?
Pricing ranges from free tiers with limited usage to enterprise plans costing $50-200 monthly. Most platforms charge per character or minute of generated audio, with bulk pricing available for high-volume users. Commercial licensing may require additional fees.
4. Is voice cloning legal for business use?
Voice cloning is legal when you have explicit consent from the voice owner or when cloning your own voice. Business applications require clear consent agreements and appropriate usage policies to avoid legal complications and ethical issues.
5. How does AI voice generation compare to human voice talent?
Automated voice synthesis offers significant cost and speed advantages while achieving near-human quality for most content types. Human talent still excels in highly emotional content, creative interpretation, and nuanced performance, but the gap continues narrowing.
6. Can AI voices be customized for specific brand requirements?
Yes, many platforms offer voice customization including tone, pace, emphasis patterns, and emotional characteristics. Advanced systems allow training custom voices that match specific brand personalities and communication styles.
7. What technical requirements are needed for AI voice integration?
Most platforms provide REST APIs requiring basic programming knowledge for integration. Cloud-based solutions need reliable internet connectivity, while on-premises options require substantial computing resources for real-time processing.
8. How does AI voice generation handle pronunciation of technical terms?
Advanced platforms include pronunciation dictionaries and allow custom phonetic spellings for technical terms. However, specialized jargon and proper nouns may require manual pronunciation guidance to ensure accuracy and consistency.
Text-to-speech technology represents a transformative innovation that's reshaping how businesses create and distribute audio content. As of 2026, the technology has matured to deliver professional-quality results while offering unprecedented scalability and cost efficiency. Organizations implementing automated voice synthesis can achieve significant competitive advantages through faster content production, broader language coverage, and enhanced accessibility features. The key to successful implementation lies in understanding both the capabilities and limitations of current technology. While voice synthesis excels in many applications, it requires thoughtful integration planning, content optimization, and quality assurance processes to achieve optimal results. Businesses that invest in proper evaluation, testing, and workflow development will realize the full potential of this powerful technology.

For organizations expanding globally or seeking to improve content accessibility, text-to-speech solutions offer an efficient path forward. The technology's continued evolution promises even greater capabilities, making it an essential tool for modern content strategy. Success depends on choosing the right platform, optimizing content appropriately, and maintaining quality standards that align with audience expectations.
About the Author
Written by the SaaS - AI-powered Localization & Translation experts at Trame. Our team brings years of hands-on experience helping businesses with SaaS - AI-powered Localization & Translation, delivering practical guidance grounded in real-world results.
