Geração de voz por IA: Guia completo sobre a tecnologia de conversão de texto em voz
Geração de voz com IA: guia completo sobre a tecnologia de conversão de texto em voz
Descubra a tecnologia de geração de voz por IA, as suas vantagens e as melhores práticas. Saiba como a IA de conversão de texto em voz cria vozes realistas para vídeos, podcasts e conteúdos.
Geração de voz por IA
Conclusão principal | Explicação |
|---|---|
Qualidade da voz da IA em 2026 | A tecnologia moderna de conversão de texto em voz produz uma voz com qualidade quase humana, com entoação natural e expressão emocional |
Suporte linguístico | As principais plataformas suportam mais de 100 idiomas, incluindo sotaques regionais e nuances culturais |
Funcionalidades de clonagem de voz | Os sistemas avançados conseguem reproduzir vozes específicas a partir de pequenas amostras de áudio para criar conteúdos personalizados |
Processamento em tempo real | A tecnologia atual permite a geração instantânea de voz para aplicações em tempo real e conteúdos interativos |
Aplicações comerciais | As empresas utilizam vozes geradas por IA em vídeos de marketing, e-learning, acessibilidade e conteúdos multilingues |
Relação custo-benefício | A síntese de voz automatizada reduz os custos de produção em 80 a 90 % em comparação com os locutores tradicionais |
Índice
O que é a geração de voz por IA?
Como funciona a geração de voz por IA
Principais vantagens da geração de voz por IA
Desafios e erros comuns
Melhores práticas para a geração de voz por IA em 2026
Fontes e referências
Perguntas frequentes
A geração de voz por IA está a revolucionar a forma como as empresas criam conteúdos de áudio, permitindo a conversão instantânea de texto em fala com um tom natural em vários idiomas. Esta tecnologia transforma conteúdos escritos em locuções realistas sem necessidade de locutores humanos, tornando a produção de áudio profissional acessível a organizações de todas as dimensões. Em 2026, esta tecnologia inovadora de conversão de texto em voz atingiu níveis sem precedentes de realismo e funcionalidade. O impacto da tecnologia vai muito além da simples conversão de texto em voz. Os sistemas de voz com IA modernos conseguem replicar características vocais específicas, manter um tom emocional consistente e até sincronizar-se com conteúdos de vídeo para experiências multimédia perfeitas. Para as empresas em expansão global, a síntese de voz automatizada oferece a capacidade de criar conteúdos localizados rapidamente, preservando simultaneamente a voz da marca em diferentes mercados.

O que é a geração de voz por IA?
A geração de voz por IA é uma tecnologia de aprendizagem automática que converte texto escrito em áudio falado, utilizando redes neurais artificiais treinadas com vastos conjuntos de dados de padrões de fala humana. Este processo, também conhecido como síntese de texto-para-voz (TTS), cria uma saída vocal realista que imita a entoação, o ritmo e a pronúncia humanos em vários idiomas e sotaques.
Componentes tecnológicos essenciais
A base da tecnologia de conversão de texto em voz assenta em várias tecnologias interligadas que funcionam em conjunto para produzir uma fala com um som natural. Os modelos de aprendizagem profunda analisam padrões linguísticos, estruturas fonéticas e propriedades acústicas para compreender a forma como os seres humanos falam naturalmente. Estes sistemas processam o texto através de múltiplas camadas de análise, desde o reconhecimento básico de palavras até à interpretação emocional complexa. As plataformas de voz com IA modernas utilizam arquiteturas de transformadores e redes adversárias generativas (GANs) para alcançar uma qualidade semelhante à humana. De acordo com uma investigação da ElevenLabs, os principais sistemas de geração de voz conseguem agora produzir uma fala praticamente indistinguível de gravações humanas em testes de audição controlados [1]. A tecnologia evoluiu dos primeiros sistemas com som robótico para plataformas sofisticadas capazes de expressar emoções e traços de personalidade.
Evolução e capacidades atuais
A evolução desde a fala computadorizada básica até à síntese de voz avançada dos dias de hoje representa décadas de progresso tecnológico. Os primeiros sistemas de conversão de texto em voz baseavam-se na síntese concatenativa, juntando fonemas pré-gravados para formar palavras. Esta abordagem produzia um resultado entrecortado e com um som pouco natural, que se identificava claramente como sendo gerado por uma máquina. Os atuais sistemas de voz com IA utilizam redes neurais treinadas com milhões de horas de dados de fala humana. Estes modelos compreendem o contexto, a emoção e as nuances linguísticas subtis que tornam a fala natural. A partir de 2026, plataformas como a Speechify e a LOVO oferecem bibliotecas de voz com centenas de vozes distintas em mais de 60 idiomas [2]. A tecnologia suporta agora a geração em tempo real, a clonagem de voz a partir de amostras mínimas e a correspondência adaptativa de tom para diferentes tipos de conteúdo.
Dica profissional: Ao avaliar plataformas de voz com IA, teste-as com o seu próprio conteúdo, em vez de utilizar guiões de demonstração. Os textos reais contêm frequentemente jargão do setor, nomes próprios e frases complexas que revelam diferenças de qualidade entre os sistemas.
Como funciona a geração de voz por IA
A síntese de voz automatizada funciona através de um processo sofisticado em várias etapas que transforma o texto introduzido numa saída de áudio com som natural, utilizando algoritmos avançados de aprendizagem automática e arquiteturas de redes neurais.
Processamento e análise de texto
O processo de geração de voz começa com uma análise exaustiva do texto, na qual os sistemas de IA analisam o conteúdo introduzido para compreender a estrutura linguística, o contexto e o significado pretendido. Os algoritmos de processamento de linguagem natural (NLP) identificam os limites das frases, os sinais de pontuação e as relações gramaticais que influenciam os padrões de fala. O sistema analisa cada palavra quanto às regras de pronúncia, padrões de acentuação e representações fonéticas. As plataformas avançadas realizam análises semânticas para compreender o contexto e os tons emocionais presentes no texto. Esta análise ajuda a determinar a ênfase vocal, o ritmo e os padrões de entoação adequados. Por exemplo, um ponto de interrogação desencadeia uma entoação ascendente, enquanto os pontos de exclamação indicam um aumento de energia e volume. O sistema identifica também nomes próprios, acrónimos e terminologia especializada que requerem um tratamento específico da pronúncia.
Processamento por redes neurais
Assim que a análise do texto estiver concluída, as redes neurais processam os dados linguísticos através de várias camadas de transformação para gerar um resultado áudio. O processamento principal envolve vários componentes especializados da rede que funcionam em sequência:
As redes de codificadores convertem tokens de texto em representações vetoriais densas que contêm informação semântica e fonética
Os mecanismos de atenção identificam relações entre palavras e frases que influenciam a pronúncia e a ênfase
As redes de descodificação transformam vetores processados em representações de espectrogramas mel das frequências de áudio
As redes de vocoder convertem espectrogramas em formas de onda de áudio finais que os seres humanos conseguem ouvir
Os sistemas modernos, como os utilizados pela Typecast e pela Canva, empregam arquiteturas de transformadores que processam frases inteiras simultaneamente, em vez de palavra a palavra [3][4]. Este processamento paralelo permite uma melhor compreensão do contexto e um fluxo de fala mais natural. As redes neurais foram treinadas com diversos conjuntos de dados de fala que representam diferentes sotaques, estilos de fala e expressões emocionais.
Dica profissional: No caso de conteúdos multilingues, opte por plataformas que treinem modelos específicos para cada idioma, em vez de utilizar modelos universais. O treino específico para cada idioma proporciona uma pronúncia mais precisa e resultados que soam mais naturais.
Todo o processo, desde a introdução do texto até à saída de áudio, é normalmente concluído em segundos, permitindo aplicações em tempo real e experiências de voz interativas. As plataformas de qualidade mantêm a consistência independentemente do comprimento do texto, ao mesmo tempo que se adaptam a vários tipos de conteúdo e contextos de fala.
Principais vantagens da geração de voz por IA
A tecnologia de conversão de texto em voz oferece vantagens significativas para as empresas que procuram uma produção de conteúdos áudio eficiente e escalável, mantendo simultaneamente a qualidade profissional e a capacidade de alcançar um público global.
Rentabilidade e escalabilidade
A produção de voz tradicional implica a contratação de locutores profissionais, a reserva de tempo de estúdio e a gestão de agendas de gravação complexas. A síntese de voz automatizada elimina estes custos indiretos, ao mesmo tempo que oferece uma capacidade ilimitada de criação de conteúdos. As empresas podem produzir horas de conteúdo de locução pelo custo de uma única sessão de gravação profissional. As vantagens da escalabilidade tornam-se particularmente evidentes para organizações que criam conteúdo multilingue. Em vez de contratar locutores para cada idioma de destino, as empresas podem gerar áudio consistente em mais de 100 idiomas utilizando plataformas como LOVO ou FreeTTS [5][6]. Esta abordagem reduz os prazos de produção de semanas para horas, mantendo os padrões de qualidade em todas as versões linguísticas. A análise de custos de relatórios do setor mostra que a síntese de voz automatizada reduz as despesas de produção de áudio em 80-90% em comparação com os métodos tradicionais. Para empresas de e-learning, agências de marketing e criadores de conteúdo, esta redução de custos permite atualizações de conteúdo mais frequentes e uma cobertura linguística mais ampla, sem restrições orçamentais.
Rapidez e consistência
A tecnologia de conversão de texto em voz produz resultados imediatos, permitindo uma rápida iteração de conteúdos e a criação de áudio em tempo real. Os criadores de conteúdos podem gerar locuções instantaneamente, testar diferentes estilos vocais e fazer revisões imediatas sem atrasos de agendamento nem custos adicionais. Esta vantagem em termos de rapidez revela-se crucial para campanhas de marketing com prazos apertados, notícias de última hora e materiais educativos dinâmicos. A consistência representa outro benefício significativo, uma vez que as vozes geradas por IA mantêm qualidade, tom e pronúncia idênticos em volumes ilimitados de conteúdo. A voz humana varia naturalmente entre sessões de gravação devido a fatores de saúde, humor e ambientais. Os sistemas de IA oferecem resultados perfeitamente consistentes, garantindo a uniformidade da voz da marca em todo o conteúdo de áudio.
Método de produção | Tempo de conclusão | Custo por hora | Flexibilidade na revisão |
|---|---|---|---|
Locutor profissional | 3 a 5 dias | 500-2000 dólares | Limitado/Caro |
Geração de voz por IA | Ata | 10-50 dólares | Ilimitado/Imediato |
TTS automatizado (Básico) | Ata | 5-20 dólares | Elevado/Instantâneo |
Na Trame, constatámos que a síntese de voz automatizada é particularmente vantajosa em projetos de localização de vídeo, nos quais a manutenção da sincronização labial em vários idiomas exige um controlo preciso da duração do áudio. Os locutores tradicionais têm frequentemente dificuldade em cumprir os requisitos exatos de sincronização, enquanto os sistemas de IA conseguem gerar áudio com sincronização perfeita, em sintonia com o conteúdo visual.
Acessibilidade e alcance global
A tecnologia de conversão de texto em voz melhora significativamente a acessibilidade dos conteúdos para pessoas com deficiência visual, dificuldades de leitura ou dificuldades de aprendizagem. As organizações podem converter instantaneamente conteúdos escritos em formato áudio, tornando a informação acessível a públicos mais amplos sem necessidade de tempo ou recursos adicionais de desenvolvimento. As capacidades multilingues desta tecnologia permitem às empresas alcançar mercados globais de forma eficiente. As empresas podem criar conteúdos áudio localizados para públicos internacionais, mantendo simultaneamente uma mensagem de marca consistente. As opções de sotaques regionais e as adaptações de pronúncia cultural garantem que o conteúdo tenha um impacto autêntico nos mercados locais.
Desafios e erros comuns
Apesar dos avanços tecnológicos significativos, a síntese de voz automatizada continua a apresentar vários desafios e erros comuns de implementação que as organizações devem compreender e resolver para uma implementação bem-sucedida.
Questões relacionadas com a qualidade e a autenticidade
Um dos desafios mais persistentes consiste em conseguir uma reprodução com um tom sempre natural, independentemente do tipo de conteúdo e do idioma. Embora a tecnologia de conversão de texto em voz tenha melhorado significativamente, certos padrões de texto continuam a revelar características artificiais. O jargão técnico, os nomes próprios e as estruturas frásicas complexas podem resultar numa pronúncia pouco natural ou num ritmo desajeitado. Entre os problemas de qualidade mais comuns, destacam-se:
Ênfase inconsistente em palavras ou frases importantes em passagens mais longas
Dificuldade em utilizar corretamente abreviaturas, acrónimos e terminologia específica do setor
Padrões de respiração anormais ou pausas que não se coadunam com os ritmos da fala humana
Desfasamentos no tom emocional, em que a voz não reflete o estado de espírito pretendido pelo conteúdo
Erros de pronúncia de nomes, lugares e termos culturalmente específicos
Um erro comum que as organizações cometem é partir do princípio de que todas as plataformas de voz com IA oferecem a mesma qualidade. Existem diferenças significativas entre os fornecedores em termos de naturalidade, suporte linguístico e funcionalidades especializadas. Realizar testes com conteúdo real, em vez de guiões de demonstração, revela essas variações de qualidade que afetam a experiência do utilizador.
Implementação e desafios técnicos
A implementação técnica apresenta frequentemente complicações inesperadas que podem comprometer projetos de síntese de voz. Surgem desafios de integração ao ligar APIs de geração de voz a sistemas de gestão de conteúdos existentes, fluxos de trabalho de edição de vídeo ou plataformas de e-learning. Muitas organizações subestimam a complexidade técnica envolvida numa integração harmoniosa. As limitações de processamento representam outro desafio significativo, particularmente para organizações com necessidades de conteúdos em grande volume. Mesmo plataformas avançadas como o QuillBot e o NoteGPT apresentam limites de utilização e atrasos de processamento durante períodos de pico de procura [7][8]. As aplicações em tempo real requerem um planeamento cuidadoso da arquitetura para lidar com a latência e garantir um desempenho consistente. As limitações de caracteres e de idioma podem restringir a flexibilidade do conteúdo. A maioria das plataformas impõe limites de caracteres por pedido de geração, exigindo a segmentação do conteúdo para materiais mais longos. Alguns sistemas têm dificuldades com conteúdos em idiomas misturados ou com requisitos de formatação especializados, comuns em documentação técnica ou materiais educativos.
Dica profissional: Teste sempre a síntese de voz automatizada com os seus piores cenários de conteúdo – manuais técnicos, documentos jurídicos ou conteúdos com uso intensivo de acrónimos. Estes testes de resistência revelam as limitações da plataforma antes da implementação total.
Considerações éticas e jurídicas
As capacidades de clonagem de voz levantam questões éticas importantes sobre o consentimento e o potencial de uso indevido. Embora a tecnologia permita aplicações legítimas, como a preservação de vozes para pacientes médicos ou a criação de vozes de marca consistentes, também abre portas para o engano e a fraude. As organizações devem estabelecer políticas claras que regulem a utilização da clonagem de voz e obter as autorizações adequadas. Questões de direitos de autor e licenciamento complicam a utilização comercial da voz com IA. Algumas plataformas restringem a utilização comercial ou exigem licenciamento adicional para aplicações empresariais. Compreender estas limitações evita complicações legais e garante a conformidade com os termos de serviço da plataforma. Surgem preocupações com a privacidade dos dados ao utilizar serviços de geração de voz baseados na nuvem. O conteúdo de texto carregado pode ser armazenado ou analisado pelos prestadores de serviços, expondo potencialmente informações comerciais sensíveis. As organizações que lidam com conteúdo confidencial devem avaliar as políticas de privacidade e considerar soluções locais, quando necessário.
Melhores práticas para a geração de voz por IA em 2026
A implementação bem-sucedida da tecnologia de conversão de texto em voz requer um planeamento estratégico, uma seleção cuidadosa da plataforma e uma otimização contínua, a fim de alcançar resultados profissionais que correspondam aos objetivos empresariais.
Seleção e otimização de plataformas
A escolha da plataforma de síntese de voz adequada depende dos casos de utilização específicos, dos requisitos de qualidade e das necessidades de integração. As plataformas líderes em 2026 oferecem vantagens distintas para diferentes aplicações. A ElevenLabs destaca-se na clonagem de voz e na expressão emocional, enquanto a Speechify se concentra na acessibilidade e nas aplicações de leitura [1][2]. Os principais critérios de avaliação para a seleção da plataforma incluem:
Qualidade e naturalidade da voz em todos os idiomas de destino
Confiabilidade da API e velocidade de processamento para as suas necessidades de volume
Capacidades de integração com fluxos de trabalho e sistemas existentes
Alinhamento da estrutura de preços com os padrões de utilização previstos
Estilos de voz disponíveis e opções de personalização
Direitos de utilização comercial e condições de licenciamento
Testar várias plataformas com conteúdo real permite uma comparação de qualidade mais precisa. Crie scripts de avaliação utilizando conteúdo empresarial real, incluindo elementos complexos como termos técnicos, nomes próprios e estruturas de frases variadas. Esta abordagem de teste revela diferenças práticas que o conteúdo de demonstração pode não revelar.
Estratégias de otimização de conteúdo
A otimização do conteúdo para a síntese de voz automatizada melhora significativamente a qualidade e a naturalidade do resultado final. Um texto bem estruturado produz melhores resultados do que um conteúdo escrito exclusivamente para ser lido. Tenha em conta a entonação vocal ao elaborar o conteúdo, incluindo pausas naturais, uma estrutura frásica clara e sinais emocionais adequados. As técnicas eficazes de otimização de conteúdo incluem:
Escrever frases mais curtas com uma estrutura clara de sujeito-verbo-objeto
Incluindo a grafia fonética de nomes próprios pouco comuns ou termos técnicos
Inserir sinais de pontuação para definir o ritmo e a ênfase desejados
Evitar abreviaturas e acrónimos excessivos que possam confundir a pronúncia
Estruturar o conteúdo com ritmos de fala naturais e um fluxo lógico
Na Trame, desenvolvemos diretrizes de conteúdo especificamente para a síntese de voz multilingue, que garantem uma qualidade consistente em todas as línguas. Estas diretrizes abordam as preferências culturais de pronúncia, a seleção de sotaques regionais e as considerações de sincronização temporal para vídeos.
Dica profissional: Crie um dicionário de pronúncia para nomes de marcas, termos de produtos e jargão do setor utilizados com frequência. A maioria das plataformas avançadas permite definir regras de pronúncia personalizadas que melhoram a consistência em todo o conteúdo.
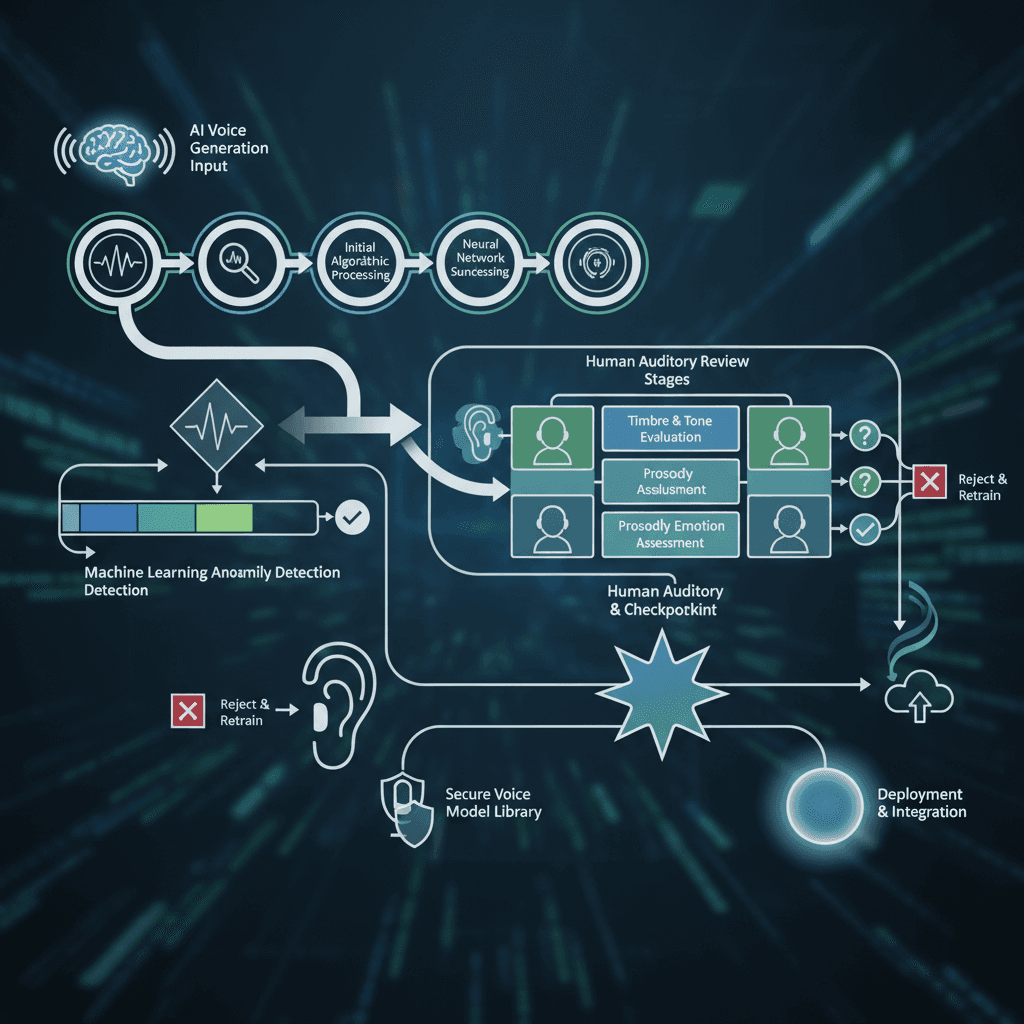
Garantia de qualidade e integração de fluxos de trabalho
O estabelecimento de processos robustos de garantia de qualidade assegura uma saída de voz gerada por IA consistente e em conformidade com os padrões profissionais. Desenvolva fluxos de trabalho de revisão que incluam tanto verificações de qualidade automatizadas como validação humana para conteúdos críticos. As ferramentas automatizadas podem identificar problemas técnicos, como artefactos de áudio ou problemas de sincronização, enquanto os revisores humanos avaliam a naturalidade e a adequação. Fluxos de trabalho eficazes de garantia de qualidade incorporam várias etapas de validação. A triagem automatizada inicial deteta problemas técnicos óbvios, seguida de uma revisão do conteúdo para verificar a precisão e a adequação do tom. A validação humana final garante que a voz gerada esteja alinhada com os padrões da marca e as expectativas do público. O planeamento da integração deve abordar considerações tanto técnicas como operacionais. A integração técnica envolve conectividade API, compatibilidade de formatos de ficheiros e automação de fluxos de trabalho. A integração operacional abrange a formação da equipa, os processos de aprovação de conteúdo e a documentação dos padrões de qualidade.
Fontes e referências
ElevenLabs, «Plataforma gratuita de geração de vozes com IA e agentes de voz», 2026
Speechify, «Gerador de vozes com IA gratuito! Locução com IA, sem necessidade de registo», 2026
Typecast, «Gerador de voz com IA e conversão de texto em voz | Ferramenta de locução», 2026
Canva, «Gerador de voz com IA: conversão de texto em voz online», 2026
LOVO, «Gerador de voz com IA gratuito e conversão de texto em voz», 2026
FreeTTS, «Conversão gratuita de texto em voz online - Gerador de voz com IA», 2026
QuillBot, «Gerador de vozes com IA gratuito | Crie locuções com IA realistas online», 2026
NoteGPT, «Gerador de vozes com IA gratuito — Crie vozes online, sem necessidade de registo», 2026
NiceVoice, «NiceVoice - Ferramenta gratuita de clonagem de voz com IA», 2026
Perguntas frequentes
1. Quão realista será a geração de voz por IA em 2026?
É essencial compreender a geração de voz por IA. A tecnologia moderna de conversão de texto em voz produz resultados extremamente realistas, que muitas vezes são indistinguíveis da fala humana em condições controladas. As principais plataformas alcançam índices de naturalidade superiores a 95% em avaliações profissionais, com melhorias contínuas na expressão emocional e na compreensão contextual.
2. A geração de voz por IA consegue lidar com vários idiomas com precisão?
Sim, as plataformas avançadas suportam mais de 100 idiomas, com pronúncia nativa e sotaques regionais. A qualidade varia consoante o idioma, sendo que os principais idiomas, como o inglês, o espanhol e o francês, recebem maior atenção em termos de desenvolvimento e apresentam as taxas de precisão mais elevadas.
3. Quais são os custos associados à geração de voz por IA?
Os preços variam entre planos gratuitos com utilização limitada e planos empresariais que custam entre 50 e 200 dólares por mês. A maioria das plataformas cobra por caractere ou por minuto de áudio gerado, estando disponíveis preços por volume para utilizadores com grande volume de utilização. A licença comercial pode implicar taxas adicionais.
4. A clonagem de voz é legal para uso comercial?
A clonagem de voz é legal quando se obtém o consentimento explícito do proprietário da voz ou quando se clona a própria voz. As aplicações comerciais exigem acordos de consentimento claros e políticas de utilização adequadas para evitar complicações legais e questões éticas.
5. Como se compara a geração de voz por IA com a voz de um locutor humano?
A síntese de voz automatizada oferece vantagens significativas em termos de custo e rapidez, ao mesmo tempo que alcança uma qualidade quase humana na maioria dos tipos de conteúdo. Os locutores humanos continuam a destacar-se em conteúdos altamente emocionais, na interpretação criativa e em performances cheias de nuances, mas a diferença continua a diminuir.
6. É possível personalizar as vozes de IA de acordo com os requisitos específicos de cada marca?
Sim, muitas plataformas oferecem personalização de voz, incluindo tom, ritmo, padrões de ênfase e características emocionais. Os sistemas avançados permitem treinar vozes personalizadas que correspondem a personalidades de marca e estilos de comunicação específicos.
7. Quais são os requisitos técnicos necessários para a integração de voz com IA?
A maioria das plataformas disponibiliza APIs REST que exigem conhecimentos básicos de programação para a integração. As soluções baseadas na nuvem requerem uma ligação à Internet fiável, enquanto as opções locais exigem recursos informáticos consideráveis para o processamento em tempo real.
8. Como é que a geração de voz por IA lida com a pronúncia de termos técnicos?
As plataformas avançadas incluem dicionários de pronúncia e permitem a definição de grafias fonéticas personalizadas para termos técnicos. No entanto, a terminologia especializada e os nomes próprios podem exigir orientações manuais de pronúncia para garantir a precisão e a consistência.
A tecnologia de conversão de texto em voz representa uma inovação transformadora que está a redefinir a forma como as empresas criam e distribuem conteúdos de áudio. Em 2026, a tecnologia atingiu um nível de maturidade que permite obter resultados de qualidade profissional, oferecendo simultaneamente uma escalabilidade e uma eficiência de custos sem precedentes. As organizações que implementam a síntese de voz automatizada podem alcançar vantagens competitivas significativas através de uma produção de conteúdos mais rápida, uma cobertura linguística mais ampla e funcionalidades de acessibilidade melhoradas. A chave para uma implementação bem-sucedida reside na compreensão tanto das capacidades como das limitações da tecnologia atual. Embora a síntese de voz se destaque em muitas aplicações, requer um planeamento de integração cuidadoso, otimização de conteúdos e processos de garantia de qualidade para alcançar resultados ótimos. As empresas que investirem na avaliação, nos testes e no desenvolvimento de fluxos de trabalho adequados irão concretizar todo o potencial desta poderosa tecnologia.

Para as organizações que se estão a expandir a nível global ou que procuram melhorar a acessibilidade dos conteúdos, as soluções de conversão de texto em voz oferecem um caminho eficiente a seguir. A evolução contínua desta tecnologia promete capacidades ainda maiores, tornando-a uma ferramenta essencial para a estratégia de conteúdos moderna. O sucesso depende da escolha da plataforma certa, da otimização adequada dos conteúdos e da manutenção de padrões de qualidade que correspondam às expectativas do público.
Sobre o autor
Escrito pelos especialistas em localização e tradução baseadas em IA para SaaS da Trame. A nossa equipa conta com anos de experiência prática a ajudar empresas com serviços de localização e tradução baseadas em IA para SaaS, oferecendo orientações práticas fundamentadas em resultados concretos.
