AI语音生成:文本转语音技术全攻略
AI语音生成:文本转语音技术全攻略
了解人工智能语音生成技术、其优势及最佳实践。了解文本转语音人工智能如何为视频、播客和各类内容生成逼真的语音。
AI语音生成
关键洞察 | 说明 |
|---|---|
2026年的AI语音质量 | 现代文本转语音技术能够生成接近人类水平的语音,具有自然的语调和情感表达 |
语言支持 | 领先的平台支持100多种语言,涵盖各地口音及文化细微差别 |
语音克隆功能 | 先进的系统能够根据短音频样本复现特定声音,从而生成个性化内容 |
实时处理 | 当前技术能够为实时应用和交互式内容提供即时语音生成功能 |
商业应用 | 企业将人工智能语音应用于营销视频、在线学习、无障碍服务以及多语言内容 |
成本效益 | 与传统配音演员相比,自动语音合成技术可将制作成本降低80%至90% |
目录
什么是人工智能语音生成?
人工智能语音生成的原理
AI语音生成的主要优势
常见的挑战与错误
2026年人工智能语音生成的最佳实践
来源与参考文献
常见问题解答
人工智能语音生成技术正在彻底改变企业制作音频内容的方式,能够将文本即时转换为多种语言的自然语音。这项技术无需真人配音员,即可将书面内容转化为逼真的旁白,使各类规模的企业都能轻松进行专业音频制作。截至2026年,这项创新的文本转语音技术在逼真度和功能性方面已达到前所未有的水平。该技术的影响远不止于简单的文本转语音转换。 现代AI语音系统能够复刻特定的嗓音特征,保持一致的情感基调,甚至能与视频内容同步,从而提供无缝的多媒体体验。对于正在全球扩张的企业而言,自动语音合成技术不仅能够快速创建本地化内容,还能在不同市场中保持品牌声音的一致性。

什么是人工智能语音生成?
AI语音生成是一种机器学习技术,它利用经过海量人类语音模式数据集训练的人工神经网络,将书面文本转换为语音。这一过程也被称为文本转语音(TTS)合成,能够生成逼真的语音输出,在多种语言和口音下模仿人类的语调、节奏和发音。
核心技术组件
文本转语音技术的基础在于多种相互关联的技术协同工作,从而生成听起来自然的语音。深度学习模型通过分析语言模式、语音结构和声学特性,来理解人类自然的说话方式。这些系统通过多层分析来处理文本,从基本的单词识别到复杂的情感解读。 现代人工智能语音平台利用Transformer架构和生成对抗网络(GAN)来实现类人级的语音质量。根据ElevenLabs的研究,在受控听觉测试中,领先的语音生成系统如今生成的语音几乎与人类录音无法区分[1]。该技术已从早期听起来像机器人的系统,演变为能够表达情感和个性特征的复杂平台。
发展历程与当前能力
从基础的计算机语音到当今先进的语音合成技术,这一历程凝聚了数十年的技术进步。早期的文本转语音系统依赖于拼接式合成,即通过拼接预先录制的音素来组成单词。这种方法产生的语音断断续续、听起来不自然,很容易被识别为机器生成的。 当前的AI语音系统利用了基于数百万小时人类语音数据训练的神经网络。这些模型能够理解语境、情感以及细微的语言差异,从而使语音听起来自然流畅。截至2026年,Speechify和LOVO等平台提供的语音库已包含60多种语言的数百种独特声音[2]。该技术现已支持实时生成、基于极少量样本的语音克隆,以及针对不同内容类型的自适应语调匹配。
专业建议:在评估AI语音平台时,请使用您实际的内容进行测试,而非演示脚本。真实文本中通常包含行业术语、专有名词和复杂句式,这些内容能充分体现不同系统之间的质量差异。
人工智能语音生成的原理
自动语音合成通过一个复杂的多阶段过程实现,该过程利用先进的机器学习算法和神经网络架构,将文本输入转换为听起来自然的音频输出。
文本处理与分析
语音生成过程始于全面的文本分析,AI系统会解析输入内容以理解语言结构、上下文及本意。自然语言处理(NLP)算法会识别句子边界、标点符号线索以及影响语音模式的语法关系。系统会对每个单词进行分析,以确定其发音规则、重音模式和语音表示形式。 先进的平台会进行语义分析,以理解文本中的上下文和情感基调。这种分析有助于确定恰当的语调强调、语速和语调模式。例如,问号会触发上扬的语调,而感叹号则表示能量和音量的增加。系统还会识别专有名词、首字母缩写词和需要特殊发音处理的专业术语。
神经网络处理
文本分析完成后,神经网络会通过多个变换层对语言数据进行处理,从而生成音频输出。核心处理过程涉及多个专用网络组件按顺序协同工作:
编码器网络将文本词元转换为包含语义和语音信息的密集向量表示
注意机制识别影响发音和重音的词语与短语之间的关系
解码器网络将处理后的向量转换为音频频率的梅尔频谱图表示
声码器网络将频谱图转换为人类可听到的最终音频波形
Typecast 和 Canva 等现代系统采用变压器架构,能够同时处理整个句子,而非逐词处理 [3][4]。这种并行处理方式有助于更好地理解上下文,并使语音表达更加自然流畅。这些神经网络是在涵盖不同口音、说话风格和情感表达的多样化语音数据集上进行训练的。
专业建议:对于多语言内容,应选择针对每种语言分别训练模型的平台,而非使用通用模型。针对特定语言的训练能产生更准确的发音和更自然的语音效果。
从文本输入到语音输出的整个过程通常只需几秒钟,从而支持实时应用和交互式语音体验。优质的平台在处理不同长度的文本时能保持一致性,同时还能适应各种内容类型和语境。
AI语音生成的主要优势
对于那些希望高效、可扩展地制作音频内容,同时又能保持专业品质并具备全球覆盖能力的企业而言,文本转语音技术带来了显著优势。
成本效益与可扩展性
传统的配音制作需要聘请专业配音员、预订录音棚时间,并管理复杂的录音日程。自动语音合成技术不仅消除了这些间接成本,还提供了无限的内容创作能力。 企业只需花费一次专业录音的费用,即可制作数小时的配音内容。对于制作多语言内容的组织而言,这种可扩展性的优势尤为显著。企业无需为每种目标语言单独聘请配音员,而是可以通过LOVO或FreeTTS等平台[5][6],生成100多种语言的统一音频。这种方法将制作周期从数周缩短至数小时,同时确保所有语言版本的质量标准一致。 行业报告的成本分析显示,与传统方法相比,自动语音合成可将音频制作费用降低80%-90%。对于在线教育公司、营销机构和内容创作者而言,这种成本降低使他们能够不受预算限制,更频繁地更新内容并实现更广泛的语言覆盖。
速度与一致性
文本转语音技术能即时产出成果,从而实现内容的快速迭代和实时音频创作。内容创作者可以即时生成旁白、测试不同的声线风格,并立即进行修改,无需等待排期或承担额外成本。这种速度优势对于时间敏感的营销活动、突发新闻内容以及动态教育材料而言至关重要。一致性是另一项显著优势,因为AI语音在处理海量内容时,始终能保持相同的质量、语调和发音。 真人配音演员在不同录音环节中,其表现会因健康状况、情绪及环境因素而自然产生差异。而AI系统能提供完全一致的输出效果,确保所有音频内容中品牌声音的统一性。
生产方法 | 完成时间 | 每小时费用 | 修订灵活性 |
|---|---|---|---|
专业配音演员 | 3-5天 | 500–2000美元 | 限量版/价格昂贵 |
AI语音生成 | 会议纪要 | 10–50美元 | 无限/即时 |
自动语音合成(基础版) | 会议纪要 | 5-20美元 | 高/即时 |
在 Trame,我们发现自动语音合成技术特别适用于视频本地化项目——这类项目需要在多种语言版本中保持口型同步,这要求对音频时长进行精确控制。传统配音演员往往难以满足精确的时长要求,而人工智能系统则能生成与视觉内容完美同步的音频。
无障碍访问与全球覆盖
文本转语音技术显著提升了视力障碍者、阅读困难者或学习障碍者获取内容的能力。企业能够将书面内容即时转换为音频格式,无需额外开发时间或资源,即可让更广泛的受众获取信息。该技术的多语言功能使企业能够高效地开拓全球市场。企业既能为国际受众制作本地化的音频内容,又能保持品牌信息的一致性。地区口音选项和文化发音的调整,确保内容能真实地引起当地市场的共鸣。
常见的挑战与错误
尽管技术取得了显著进步,自动语音合成仍面临诸多挑战和常见的实施误区,企业必须充分了解并解决这些问题,才能成功部署该技术。
质量与真伪问题
一个长期存在的难题在于,如何在不同内容类型和语言之间实现始终如一的自然语音输出。尽管文本转语音技术已取得长足进步,但某些文本模式仍会暴露其生硬的特征。专业术语、专有名词和复杂的句式结构可能会导致发音不自然或语速不流畅。常见的质量问题包括:
在较长的段落中,对重要词语或短语的强调不够一致
难以正确处理缩写、首字母缩写词和行业专用术语
与人类说话节奏不符的异常呼吸模式或停顿
情感基调不符,即声音未能体现内容所传达的情绪
人名、地名及文化专有名词的发音错误
许多组织常犯的一个错误是,以为所有人工智能语音平台提供的质量都一样。实际上,各供应商在语音自然度、语言支持和专业功能方面存在显著差异。使用实际内容而非演示脚本进行测试,才能揭示这些影响用户体验的质量差异。
实施与技术挑战
技术实现过程中常会出现意料之外的复杂情况,这些情况可能导致语音合成项目脱轨。在将语音生成 API 与现有内容管理系统、视频编辑工作流或在线学习平台进行集成时,往往会遇到整合难题。许多组织低估了无缝集成所涉及的技术复杂性。处理能力限制是另一个重大挑战,对于内容需求量大的组织而言尤为如此。即使是 QuillBot 和 NoteGPT 这样的高级平台,在需求高峰期也会面临使用限制和处理延迟的问题 [7][8]。 实时应用需要周密的架构规划,以应对延迟并确保性能稳定。字符和语言限制可能限制内容的灵活性。大多数平台对每次生成请求都设定了字符限制,因此长篇内容需要进行分段处理。部分系统难以处理混合语言内容,或无法满足技术文档及教育材料中常见的特殊格式要求。
专业建议:在测试自动语音合成功能时,请务必使用最棘手的文本内容进行测试——例如技术手册、法律文件或大量使用缩写词的内容。这些压力测试能在全面部署前揭示平台的局限性。
伦理与法律考量
语音克隆技术引发了关于同意权及潜在滥用风险的重要伦理问题。虽然该技术能够支持诸如为医疗患者保存声音或打造统一的品牌声音等正当应用,但也为欺骗和诈骗提供了可乘之机。各组织必须制定明确的政策来规范语音克隆的使用,并获得相应的授权。 版权和许可问题使商业AI语音应用变得复杂。部分平台限制商业用途,或要求企业应用需额外获取许可。了解这些限制有助于避免法律纠纷,并确保遵守平台的服务条款。使用基于云的语音生成服务时,会引发数据隐私问题。上传的文本内容可能被服务提供商存储或分析,从而可能泄露敏感的商业信息。处理机密内容的组织必须评估隐私政策,并在必要时考虑采用本地部署的解决方案。
2026年人工智能语音生成的最佳实践
要成功实施文本转语音技术,需要进行战略规划、审慎选择平台并持续优化,从而获得符合业务目标的专业成果。
平台选择与优化
选择合适的语音合成平台取决于具体的使用场景、质量要求以及集成需求。2026年的领先平台在不同的应用场景中各具优势。ElevenLabs 在语音克隆和情感表达方面表现出色,而 Speechify 则专注于无障碍辅助和朗读应用 [1][2]。平台选择的关键评估标准包括:
目标语言中的语音质量与自然度
满足您业务量需求的API可靠性和处理速度
与现有工作流和系统的集成能力
定价结构与预期使用模式保持一致
可用的语音风格和自定义选项
商业使用权及许可条款
使用真实内容对多个平台进行测试,能提供最准确的质量对比。请使用真实的业务内容编写评估脚本,其中应包含技术术语、专有名词和多样化的句式结构等具有挑战性的元素。这种测试方法能够揭示演示内容可能无法体现的实际差异。
内容优化策略
针对自动语音合成进行内容优化,能显著提升输出质量和自然度。结构清晰的文本比仅供阅读的内容能产生更好的效果。在创作内容时,应考虑语音表达的特点,包括自然的停顿点、清晰的句式结构以及恰当的情感线索。有效的内容优化技巧包括:
写出结构清晰、主谓宾明确的简短句子
为不常见的专有名词或术语添加音标
添加标点符号以控制语速和强调重点
避免使用过多的缩写和首字母缩略词,以免造成发音上的混淆
以自然的语调和逻辑连贯性来组织内容
在 Trame,我们专门针对多语言语音合成制定了内容指南,以确保不同语言间质量的一致性。这些指南涵盖了文化发音偏好、地区口音选择以及视频同步的时间安排等要点。
专业建议:为常用品牌名称、产品术语和行业行话创建发音词典。大多数高级平台都支持自定义发音规则,有助于确保所有内容的一致性。
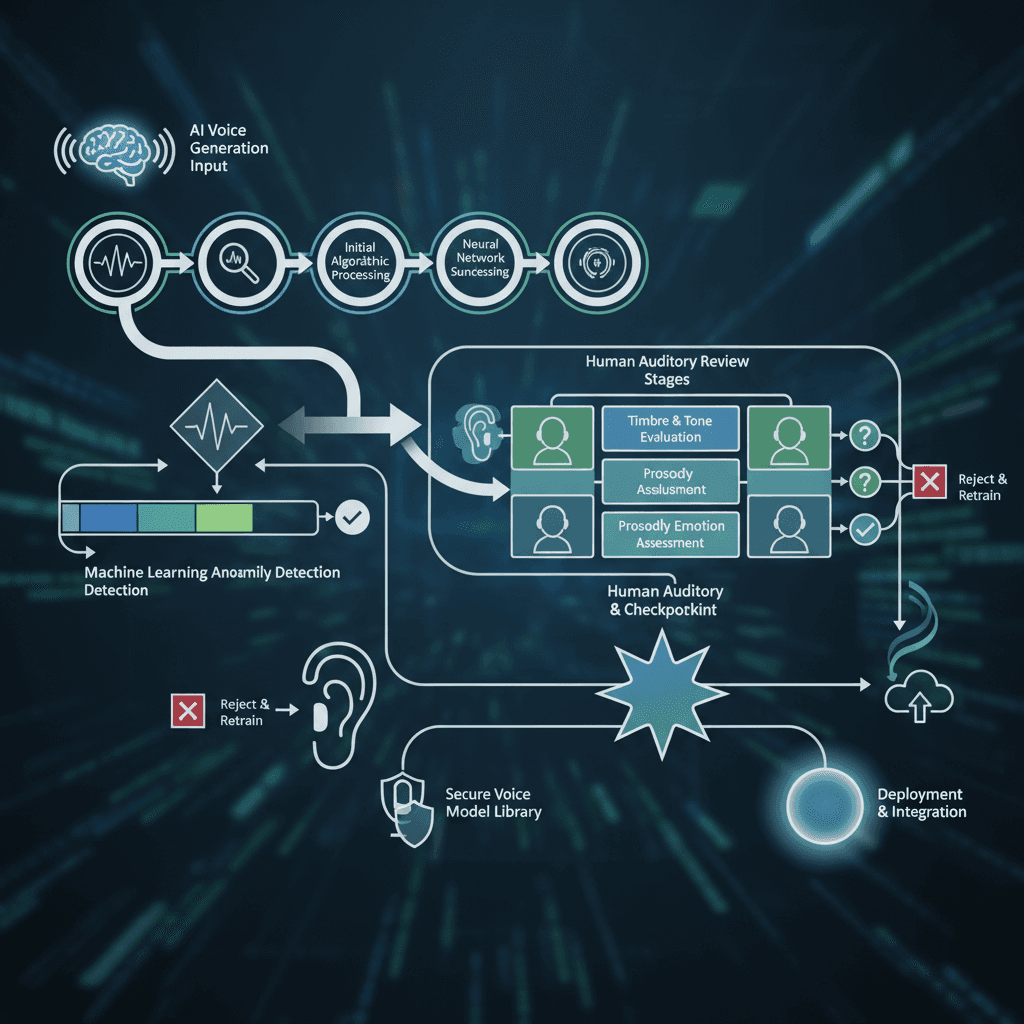
质量保证与工作流集成
建立健全的质量保证流程,可确保AI语音输出保持一致并符合专业标准。应制定包含自动化质量检查和关键内容人工验证的审核工作流。自动化工具可识别音频失真或时间同步问题等技术问题,而人工审核员则负责评估语音的自然度和恰当性。 有效的质量保证工作流应包含多个验证阶段。首先通过自动化筛查发现明显的技术问题,随后进行内容审核以确保准确性和语气恰当。最后由人工验证,确保生成的语音符合品牌标准和受众期望。集成规划应兼顾技术和运营方面的考量。技术集成涉及 API 连接、文件格式兼容性以及工作流自动化。运营集成则涵盖团队培训、内容审批流程以及质量标准文档的制定。
来源与参考文献
常见问题解答
1. 到2026年,人工智能生成的语音听起来会有多逼真?
了解人工智能语音生成技术至关重要。现代文本转语音技术生成的效果极其逼真,在受控环境下往往难以与人类语音区分。领先平台在专业评估中自然度评分超过95%,且在情感表达和语境理解方面持续取得进步。
2. 人工智能语音生成技术能否准确处理多种语言?
是的,先进的平台支持100多种语言,并提供原生发音和地区口音。不同语言的质量有所差异,英语、西班牙语和法语等主要语言获得了最多的开发关注,准确率也最高。
3. 人工智能语音生成涉及哪些成本?
价格范围从使用受限的免费套餐到每月50至200美元的企业套餐不等。大多数平台按生成的音频字符数或分钟数收费,并为大用户量用户提供批量优惠。商业授权可能需要额外费用。
4. 语音克隆在商业用途中是否合法?
在获得声音所有者的明确同意或克隆自身声音的情况下,声音克隆是合法的。商业应用需制定明确的同意协议和适当的使用政策,以避免法律纠纷和伦理问题。
5. 人工智能语音生成与真人配音相比如何?
自动语音合成技术不仅在成本和速度方面具有显著优势,而且对于大多数内容类型都能达到接近人类的声音质量。虽然人类配音员在情感浓厚的内容、创意演绎和细腻表现方面仍具优势,但两者之间的差距正在不断缩小。
6. 人工智能语音能否根据特定品牌需求进行定制?
是的,许多平台都提供语音定制功能,包括语调、语速、重音模式以及情感特征。先进的系统还支持训练定制语音,以契合特定的品牌个性与沟通风格。
7. 人工智能语音集成需要满足哪些技术要求?
大多数平台提供的 REST API 需要具备基本的编程知识才能进行集成。基于云的解决方案需要稳定的互联网连接,而本地部署方案则需要大量的计算资源来支持实时处理。
8. 人工智能语音生成技术如何处理技术术语的发音?
高级平台包含发音词典,并支持为专业术语自定义音标拼写。不过,针对专业术语和专有名词,可能需要手动提供发音指引,以确保准确性和一致性。
文本转语音技术是一项具有变革性的创新,正在重塑企业制作和分发音频内容的方式。截至2026年,该技术已日趋成熟,不仅能提供专业级别的音质,还具备前所未有的可扩展性和成本效益。 采用自动语音合成技术的组织,可通过更快的内容制作速度、更广泛的语言覆盖范围以及增强的无障碍功能,获得显著的竞争优势。成功实施的关键在于既要了解当前技术的优势,也要认识到其局限性。虽然语音合成在许多应用场景中表现出色,但要取得最佳效果,仍需周密的集成规划、内容优化以及质量保证流程。那些在评估、测试和工作流程开发方面投入足够资源的企业,将能够充分发挥这项强大技术的全部潜力。

对于正在全球扩张或希望提升内容可访问性的组织而言,文本转语音解决方案提供了一条高效的途径。该技术的持续发展将带来更强大的功能,使其成为现代内容策略中不可或缺的工具。成功的关键在于选择合适的平台、对内容进行适当优化,并保持符合受众期望的质量标准。
关于作者
本文由Trame 的 SaaS - 人工智能驱动的本地化与翻译专家团队撰写。我们的团队拥有多年实践经验,致力于为企业提供 SaaS - 人工智能驱动的本地化与翻译服务,并基于实际成果提供切实可行的指导。
